 |
 |
 |
| Home | More Articles | Join as a Member! | Post Your Job - Free! | All Translation Agencies |
|
|||||||
|
|
Using XML technology to reduce the cost of authoring and translation
At the recent LISA Forum Europe in London, Andrzej Zydron reported on the history of publishing formats and the development of a new XML-based format for translation and authoring memory called xml:tm. xml:tm leverages the architecture of XML to allow XML-based documents to contain multiple language versions, translation information, revision history and other important information that enables end-users to much more easily handle many aspects of a document’s creation and subsequent use. In this article Zydron describes xml:tm and its benefits for users of XML-based publishing formats. A Little History…
The problem was exacerbated by the veritable “Tower of Babel” of differing authoring and composition environments from Interleaf through to PageMaker. The typical approach was to write filters that would “lift” the text to be translated from its proprietary embedded environment and to present it to translators in a uniform but equally proprietary translation environment. After translation the text would then be merged with the original document, replacing the source language text. ISO 8879:1986 SGMLA serious attempt to tackle the plethora of competing formats and their embedded nature was made in 1986 with the advent of ISO 8879 Standard Generalized Markup Language (SGML). This attempted to separate the content of documents from their form. SGML arose at a time of great and rapid change in the IT industry. The architects attempted to make the standard as flexible and open to change as possible. This laudable aim unfortunately produced something that was very difficult and expensive to implement. In addition SGML only tackled the aspect of content. Form was tackled by ISO/IEC 10179:1996 Document Style Semantics and Specification Language (DSSSL), but this proved equally difficult to implement. HTMLThe efforts of the ISO 8879 committee were not in vain. SGML allowed for the creation of HTML which allowed the early World Wide Web to catapult the Internet from a vehicle used by academics and computer scientists to what we know today. HTML was initially based on strict adherence to the SGML standard, but soon diverged as the limitations of ISO 8879 became apparent. XMLBy 1996 the World Wide Web Consortium (W3C) began to look for a solution that was better than HTML. What was required was something that would allow for the semantic exchange of information. It needed to be able to propel the Internet from displaying only static pages to a core semantic web, allowing for the exchange of data. The efforts of W3C resulted in XML 1.0. This addressed many of the architectural limitations of SGML, allowing for easier manipulation and parsing of the semantics. In addition to many very good features, the architects of XML introduced a powerful new feature called “namespace”. XML Namespace allows for the mapping of more than one representation of meaning onto a given document. This feature is now used extensively in supporting standards such as XSL, XSLT, XML Schema and FOP. The FutureThe success of XML has been phenomenal, although much of its success has yet to become visible to end users. It is now driving the future of the World Wide Web through providing the foundation for important web standards such as XML Web Services, electronic data exchange, etc. It has spawned much feverish activity in the developer community and has created some excellent Open Source tools and libraries such as those provided by the Apache foundation (xml.apache.org) and Source Forge (www.sourceforge.net). Even strongly proprietary companies have had to accept the importance of XML. Much excellent work is also being conducted by standards organizations such as OASIS (www.oasis-open.org) and W3C (www.w3c.org) XML based standards, including XLIFF for the translation of documents. Our premise is that the case for XML is so compelling that all leading vendors of word processing and composition systems will have to support it in the near future. In terms of translation the arguments are even more convincing. It can be up to five times more expensive to translate and correct the layout of documents written in proprietary systems than in XML. Sun Microsystems (www.sun.com) along with the OpenOffice organization (www.openoffice.org), already supplies an excellent XML based alternative to proprietary systems, which can also read proprietary systems such as Word and convert them to XML. Microsoft has also announced support for XML in the next version of Office. With this view of the future in mind, we have concentrated our efforts on how best to exploit the very rich syntax and capabilities of XML. xml:tmxml:tm radically changes the approach to the translation of XML-based documents. It is an Open Standard created and maintained by xml-Intl, for the benefit of those involved in the translation of XML documents. At the core of xml:tm is the concept of “text memory,” made up of two components:
Author MemoryXML namespace is used to map a text memory view onto a document. This process is called segmentation. The text memory view works at the sentence level of granularity – the text unit. Each individual xml:tm text unit is allocated a unique identifier. This unique identifier is immutable for the life of the document. As a document goes through its life cycle, the unique identifiers are maintained, while new ones are allocated as required. This aspect of text memory is called “author memory.” It can be used to build author memory systems to simplify and improve authoring consistency. The following diagram shows how the tm namespace maps onto an existing xml document: 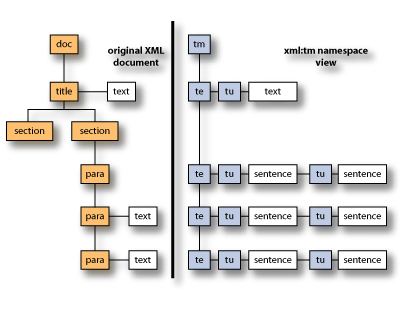
In the above diagram, "te" stands for "text element" (an XML element that contains text) and "tu" stands for "text unit" (a single sentence or stand alone piece of text). The following is an example of part of an xml:tm document. The xml:tm elements are highlighted in red to show how xml:tm maps onto an existing XML document.:
And the composed document: 
Translation MemoryWhen an xml:tm namespace document is ready for translation, the namespace itself specifies the text that is to be translated. The tm namespace can be used to create an XLIFF document for translation. (XML Localization Interchange File Format [XLIFF] is an OASIS standard that is optimized for translation. Please refer to the section below entitled XLIFF and Online Translation for more information.) When the translation of XLIFF files has been completed, the target language text can be merged with the original document to create a new target language version of that document. The net result is a perfectly aligned source and target language document. The following is an example of a translated xml:tm document: <?xml version="1.0" encoding="UTF-8" ?> <office:document-content xmlns:text="http://openoffice.org/2000/text" xmlns:tm="urn:xmlintl-tm-tags" xmlns:xlink="http://www.w3.org/1999/xlink"> <tm:tm> .......... <text:p text:style-name="Text body"> <tm:te id="e1" tuval="2"> <tm:tu id="u1.1">Xml:tm es un técnica revolucionaria que trata los problemas de memoria de traducción en documentos XML usando técnicas XML e incluyendo la memoria en el documento mismo.</tm:tu> <tm:tu id="u1.2">Esta técnica hace extensor uso de XML namespace.</tm:tu> </tm:te> </text:p> <text:p text:style-name="Text body"> <tm:te id="e2"> <tm:tu id="u2.1">“tm” significa “memoria de texto”.</tm:tu> <tm:tu id="u2.2">Hay dos aspectos de memoria de texto:</tm:tu> </tm:te> .......... This is an example of the composed translated text: 
The source and target text is linked at the sentence level by the unique xml:tm identifiers. When the document is revised, new identifiers are allocated to modified or new text units. When extracting text for translation of the updated source document the text units that have not changed can be automatically replaced with the target language text. Different Types of MatchingThe matching described in the previous section is called “perfect” matching. xml:tm offers unique TM matching possibilities to reduce the quantity of text for translation and to provide the human translator with alternative translations. The following diagram shows how Perfect Matching is achieved: 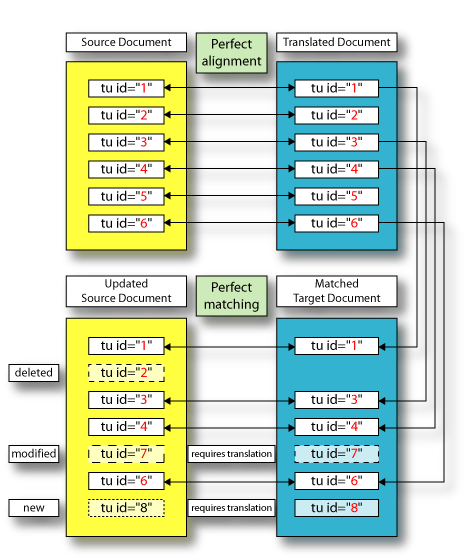
The following types of matching are available:
The following is an example of non-translatable text in xml:tm: ......................
And an example of the composed text: 
Word CountsThe output from the text extraction process can be used to generate automatic word and match counts by the customer. This puts the customer in control of the word counts. XLIFF OnLine translation.XLIFF is an OASIS standard for the interchange of translatable text in XML format. xml:tm translatable files can be created in XLIFF format. The XLIFF format can then be used to create dynamic web pages for translation. A translator can access these pages via a browser and omplete the entire translation process over the Internet. This has many potential benefits. The challenges posed by (1) filters, (2) delays inherent in sending data out for translation, (3) inadvertent corruption of character encoding or document syntax, and (4) simple human work-flow problems can be totally avoided. By applying XML technology, it is now possible to both decrease and control the cost of translation, as well as reduce the time it takes while improving reliability. An example of a web-based translator environment can be seen at the following web address: http://www.xml-intl.com/demo/trans.html Benefits of Using xml:tmThe following is a list of the main benefits of using the xml:tm approach to authoring and translation:
Summaryxml:tm is an Open Standard created and maintained by xml-Intl based on XML and XLIFF. Full details of the xml:tm definitions (XML Data Type Definition and XML Schema) are available from the xml-Intl web site (http://www.xml-intl.com). Xml-Intl also supplies an implementation of xml:tm using Java and Oracle, which includes linguistically aware database leveraged and fuzzy matching. xml:tm is best suited to enterprise-level implementation for corporations with large annual translation requirements and content management systems. During the implementation process, xml:tm is integrated with the customer’s content management system. xml:tm reduces translation costs in the following ways:
was born in England. Educated in France he started working in IT in 1976. His experience has covered all aspects of computing, with in depth knowledge of Software Engineering, SGML, XML, encoding methodologies and translation memory. Highlights of his career include:
Currently he is developing the next generation of XML based “text memory” systems, which offer substantial benefits by reducing the costs for authoring and translation of XML based documents. Andrzej Zydron is a member of the British Computer Society. He is also technical and research director of xml-Intl Ltd. and sits on the OASIS technical committee for Translation Web Services.
Reprinted
by permission from the Globalization Insider,
26 August 2003, Volume XII, Issue 3.5. Copyright the Localization Industry Standards Association (Globalization Insider: www.localization.org, LISA: www.lisa.org) and S.M.P. Marketing Sarl (SMP) 2004
E-mail this article to your colleague! Need more translation jobs? Click here! Translation agencies are welcome to register here - Free! Freelance translators are welcome to register here - Free! |
|
|
Legal Disclaimer Site Map |
 The advent of text in electronic format posed a number
of problems for translators. These problems were:
The advent of text in electronic format posed a number
of problems for translators. These problems were:
