 |
 |
 |
| Home | More Articles | Join as a Member! | Post Your Job - Free! | All Translation Agencies |
|
|||||||
|
|
Teaching Computers: Building Multilingual Linguistic Resources With Volunteer Contributions Over the Web
One of the
most compelling powers of the internet lies in its
ability to instantly link a massive number of people
and share their knowledge on any subject at little
cost. In the following article, researchers Dr. Rada
Mihalcea and Dr. Timothy Chklovski outline their project,
Teach-Computers,
which aims to build high-performance natural language
processing tools through tapping into people’s understanding
of common words via a simple click on the Web.
Helping Computers Help Us  Being able to understand another language is nothing
to be taken lightly. Anyone who has ventured into
a foreign country without speaking the language will
attest to the difficulties that can arise when wild
gesticulation attempts to replace language in requesting
a vegetarian dish or enquiring about the arrival of
the next train.
Being able to understand another language is nothing
to be taken lightly. Anyone who has ventured into
a foreign country without speaking the language will
attest to the difficulties that can arise when wild
gesticulation attempts to replace language in requesting
a vegetarian dish or enquiring about the arrival of
the next train.
Thanks to the world wide web, similar angst can arise in written communication from the comfort of your own room or even a mobile device. A product has been out in Japan for several months and is about to hit the shelves in the U.S. What do the Japanese customers think of it? The reviews are right there, on the web – but the fact that the pages are likely to be in Japanese is of little help to the vast majority of potential American customers. In a commendable move, MIT is making all of their course materials available for free on the web though the Open CourseWare project. However, the impact of wonderful education resources such as these would be even more pervasive if those who do not speak (actually, read) English could use the resources. These examples hint at nothing less than the concept of universal communication – borderless communication between people, regardless of the language they speak. But how can we get there? When learning a new language, one human faculty that is sorely stressed is memory. Some words, even recently learned, slip our mind. Only when we become practiced does the task of selecting the right expression for simple statements become second nature, in other words, a simple routine task. While still laden with many limitations, computers are difficult to fault for their ability to store information or to carry out tasks so fraught with the routine that they would bring tears of boredom to the eyes of the staunchest accountant. Only one step remains before computers can set about the knowledge-heavy tasks of discerning meanings and generating languages. That step is to first teach them, for a variety of contexts, which word meanings and which translations are actually intended. Teach Computers aims to tap people’s ability to handle language and to give computers the benefit of that knowledge. The goal of the Teach Computers project is exactly that – to create an environment where people can teach computers and help them to help us. It is a Web-based project that aims to tap people’s ability to handle language and to give computers the benefit of that knowledge. Any Web user can visit the Teach-Computers.org site and contribute some of their knowledge, which will then be used to develop intelligent computer programs that can understand, generate and learn natural language. The project also tries to make the most of every contributor’s effort with active learning. When possible, the site automatically selects for human annotation only those examples that would be most useful – for example, those that baffle automatic tagging systems. The system is expected to yield more training data of comparable quality and at a significantly lower cost than the traditional method of hiring lexicographers. Natural Language Processing Is Data Hungry!Natural Language Processing (NLP) is a field right at the nexus between Computer Science and Linguistics, concerned with creating computer programs that can understand, generate and learn natural language. Computer programs that should ideally work for any kind of natural language, and that should be capable of tackling any of the 7,200 languages spoken worldwide. NLP researchers are developing programs that can perform automatic translations, run intelligent searches on the Web, extract the essence of texts, find jobs on the Internet, recommend new movies or songs based on one’s preferences, etc. Most of these applications are possible because computers can be equipped to learn how to perform these tasks by being fed examples of how people perform them. For instance, there are computer programs that can learn how to do a good translation between English and French through training on several hundreds of thousands of sentences translated by bilingual English-French speakers. Other automated systems can search the billions of words available in a variety of languages and retrieve the information you need in a language you know. And so on. How about German-Hindi? Or Spanish-Chinese? Or English-Romanian? All this is possible, but it is also closely tied to the amount of human-produced data that is available for computers to learn from. There are thousands of existing translated sentences for English-French, thanks mostly to the bilingual publications available in Canada. But how about German-Hindi? Or Spanish-Chinese? Or English-Romanian? If you want a similar system that does reasonable automatic translations to allow you to read Romanian newspapers without knowing much about the language, you would need a lot of translated sentences between English and Romanian – a text collection that, unfortunately, is not available. Similar to the automatic translation problem, many other NLP applications have benefited from and could use more human teaching. These applications are “data hungry,” but the data are not readily available. To achieve the performance level of 95% in determining the English parts of speech requires annotation of about 3 million words (with their parts of speech) as they occur in real sentences. Few languages of the world have anything close to that much part-of-speech data available. Another annotation effort – that required about 2 person-years of work – resulted in approximately 600,000 words being annotated with the parse structure of their sentences. It requires this much data to train a state-of-the-art syntactic parser of English, whose accuracy now approaches 90%. Similar progress in other languages is yet to be seen. In order to enable applications close to human-level performance, computers need large amounts of annotated texts, which oftentimes represents a bottleneck in developing such technologies. There are only a few English-Romanian parallel texts. And still, there are 23 million speakers of Romanian. If only 1% of them are also English speakers, and if 1% of these bilingual speakers would contribute some ten translated sentences, we would already have a fairly decent-sized bilingual corpus that could be used to teach computers how to translate between these two languages. The Teach-Computers project is designed to contribute to solving this problem through deploying knowledge capture systems over the Web to tap into people’s ability to deal with language, and thus produce the data so critically needed to build high-performance NLP tools. The Quest for MeaningOne of the most difficult problems in NLP is word sense disambiguation – the problem of finding the correct meaning of a word, given its context. Many automatic language processing tools depend on how machines “make sense” of the text they are to process. Determining a word’s meaning affects both the way we translate the word and the way we conduct an information search containing that word. Ambiguity is very common (especially among the most common words – think about table, or computer fan), but people are so good at figuring it out from context that they usually do not even notice it. Open Mind Word Expert creates large, sense-tagged corpora that can be used to build automatic word sense disambiguation systems. Open Mind Word Expert is one of the Web-based knowledge capture systems developed under the Teach-Computers project. It is designed to help computers to solve the word sense disambiguation problem. Any Web user can visit the Open Mind Word Expert site and contribute some knowledge about the meanings of given words in given sentences. As a result, Open Mind Word Expert creates large, sense-tagged corpora that can be used to build automatic word sense disambiguation systems. When contributors visit the Open Mind Word Expert site, they are presented with a set of natural language (e.g., English) sentences that include an instance of the ambiguous word. They are asked to indicate the most appropriate meaning with respect to the definitions provided. The illustration below shows the screen that users see when annotating instances for the ambiguous verb to rule.
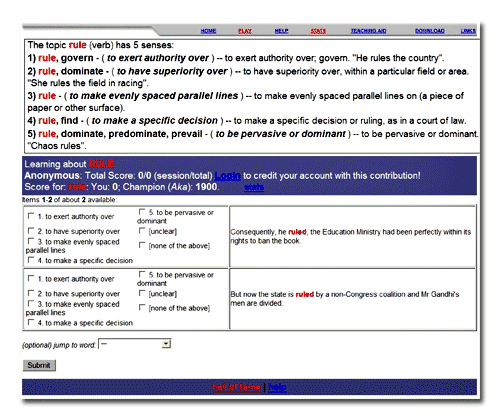
Open
Mind Word Expert – Annotation
screen Hundreds of thousands of tags have been collected since the site's launch two years ago. Annotations are currently being collected for building word sense disambiguation tools for English (English Open Mind Word Expert) and Romanian (Romanian Open Mind Word Expert), and for creating English-Hindi translation tools (English-Hindi Open Mind Word Expert). The data collected so far has been used in international system evaluations (Senseval), in which computer programs built by research teams from around the world learn how to find the meaning of words using the annotations produced by the Open Mind Word Expert users. Instructors of college or even high school courses that have to do with words and their meanings can also use the site as a teaching aid. An instructor can create an activity code that allows users to access the amount tagged by each participant, along with the percentage agreement of the tagging of each contributor. Hence, instructors can assign Open Mind Word Expert tagging as part of a homework assignment or a test. Summing UpOnce collected, a piece of knowledge or an annotation can be stored and reused by a computer many times on tasks that would otherwise need to be tediously carried out “by hand.” Encouraged by the knowledge collected and methodological refinements to date (weeding out disagreements in annotations, malicious misannotations and so on), we are interested in extending the approach to other languages and collecting richer information about what people mean when they use language. We encourage you to visit the site and contact us if you think it may be useful in one of your projects. The Teach-Computers project is accessible here, with links to all the Web-based knowledge capture systems that we have developed so far, including the various Open Mind Word Expert systems. Additional details can be found in publications available on-site.
Dr. Rada Mihalcea (http://www.cs.unt.edu/~rada/) is an Assistant Professor of Computer Science at the University of North Texas. Her research interests are in lexical semantics, minimally supervised natural language learning, graph-theoretical methods for text processing and multilingual natural language processing. Dr. Timothy Chklovski (http://www.isi.edu/~timc) is a Research Scientist at the Information Sciences Institute at the University of Southern California. His interests include cognitive augmentation (tools that help people think, build arguments and make decisions), knowledge representation and lexical semantics. Previously, he co-founded and ran aQuery, a venture-funded company focused on document understanding.
Reprinted
by permission from the Globalization Insider,
14 September 2004, Volume XIII, Issue 3.3. Copyright the Localization Industry Standards Association (Globalization Insider: www.localization.org, LISA: www.lisa.org) and S.M.P. Marketing Sarl (SMP) 2004
E-mail this article to your colleague! Need more translation jobs? Click here! Translation agencies are welcome to register here - Free! Freelance translators are welcome to register here - Free! |
|
|
Legal Disclaimer Site Map |
 One step remains before
computers can set about discerning meanings and
generating languages.
One step remains before
computers can set about discerning meanings and
generating languages.
