|
 |
 |
| Home | More Articles | Join as a Member! | Post Your Job - Free! | All Translation Agencies |
|
|||||||
|
|
The best freeware corpus analysis program for translators?
1. Introduction
My experience with corpus analysis tools is based mainly on my work in training Finnish student translators to translate into English. In earlier articles, several of which are viewable online (see, for example, Wilkinson 2005a & 2005b), I have shown how a monolingual target-language corpus of texts can be a useful performance-enhancing tool in translating by giving examples of search strategies that can help the translator to choose an appropriate translation equivalent. The results of the search strategies were generated by the commercially-available software WordSmith Tools version 4 (Scott 2004) and version 5 (Scott 2008). I recently examined the pros and cons of WordSmith Tools in meeting the needs of the translator (Wilkinson 2011). I focused on its concordancer, since this is the tool that is of most direct use as a translation aid. The concordancer finds all the occurrences of a search word, or search pattern, in a chosen corpus and shows them in the centre of the display window together with a span of co-text to the left and right. I concluded that WordSmith Tools is, at least in my experience, the best commercially-marketed corpus analysis program available to translators. However not all translators – and especially student translators – are prepared to invest in such software, especially if they are uncertain whether they will be using it on a large scale. One solution is to turn to a freeware program such as AntConc. 2. About AntConc The first version of AntConc was released in 2002 by Laurence Anthony. It was a simple concordance program, but since then it has undergone continuous improvement and development. The most recent “stable-release” version at the time of writing (February 2012) is AntConc 3.2.4 (Anthony, 2011). AntConc can run on Windows, Macintosh and Linux operating systems, but whereas WordSmith requires additional software to run on systems other than Windows, AntConc runs on all three systems without additional software. In addition, AntConc is able to process texts in almost any language in the world, including Asian languages, such as Chinese, Japanese, and Korean. Moreover AntConc can process both UTF-8 and all legacy encodings on different systems, so it should be able to process texts saved in the operating system default encoding on all systems. Like WordSmith, AntConc comprises, in addition to the concordancer, various other features, such as a tool for generating word-lists as well as a keyword tool that can locate and identify words that occur with an unusually high (or low) frequency in a corpus when it is compared with a reference corpus. However in the following I shall focus mainly on how well the concordancer serves the needs of the translator. 3. The translator’s needs In my examination of WordSmith, I suggested that a good concordancer should have all or most of the following features:
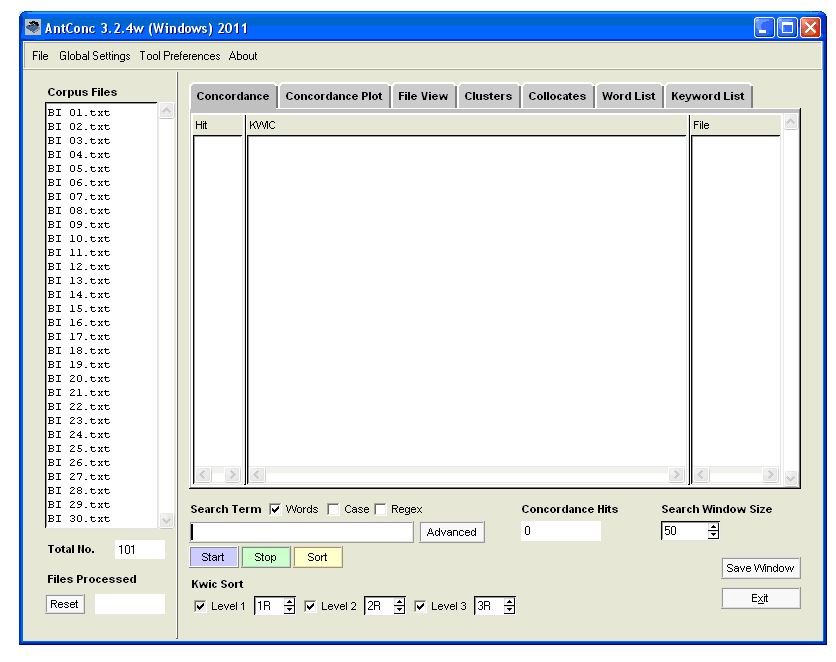
Figure 1. Features of a good concordancer Below I will discuss whether AntConc 3.2.4 fulfils the requirements listed in Figure 1. I have run the program only on Windows, so I cannot vouch for its performance on other operating systems. Moreover I have used the program only with English-language corpora and Finnish-language corpora (which do include the unusual characters ä and ö), so I am unable to comment on its performance with corpora of texts comprising non-western language characters. 3.1 Learnability & usability For anyone who is already familiar with corpus analysis tools, the basic features are easy to learn and use. As pointed out by Maher et al (2008) in their article on acquiring or enhancing a translation specialism, AntConc has “a user-friendly concordancer with an intuitive interface”. Being familiar with WordSmith, I was able to select a corpus, search for words, use wild cards, sort the concordance lines, and view in a wider context without difficulty. However I encountered some difficulties with some of the more advanced features, which I will touch on later. For those who are totally new to corpus analysis tools, there is plenty of help on the AntConc Homepage. For example the Readme File (available in English, Chinese, German and Korean) and an on-line help system that can be accessed from there provide information about the concordancer as well as about other tools and features, and in addition there is a variety of excellent video tutorials (available in English and Japanese). 3.2 Selecting a corpus Choosing a corpus to analyse is very straightforward – from the File menu in the top left corner, you select files for processing by using either the Open File(s) or Open Dir options. Figure 2 shows the view I get after choosing the 101 files of my self-compiled corpus of texts from British, US & Canadian tourist brochures. The total size of the corpus amounts to around 1,075,000 words, and can be regarded as comprising three approximately equal-sized sub-corpora. The file names have been labelled with one of the following codes: BI, CA, US, so that the user can identify whether a concordance line is from the British Isles, Canada, or the United States. In the window on the left of the display, you can see the first 30 files of the corpus, and below that the total number of files.
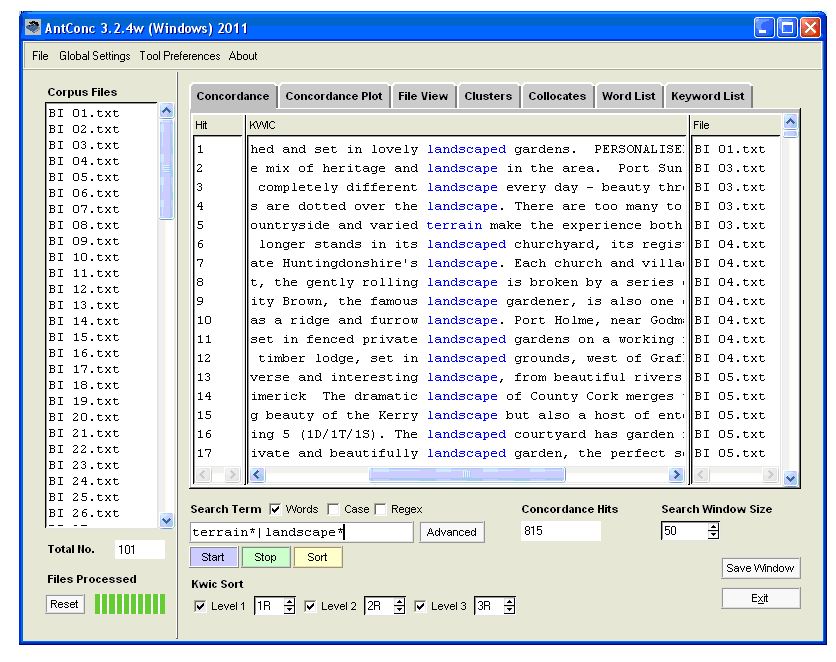
Several wildcards are at your disposal to enable flexible search patterns. They are described under Global Settings on the top toolbar, and include the asterisk, denoting zero or more characters; the plus sign, denoting zero or one character; and the question mark, denoting any one character. The plus sign and question mark can come in handy when you want your search to include both the British and American spellings of a word, as for example in the search patterns colo+r* and organi?ation*. In addition, the vertical-line wildcard enables you to search for more than one search pattern at a time. These wildcard symbols are editable, i.e. they can easily be customised via the Global Settings to suit your own preferences. I enter the search pattern terrain*|landscape* and press Start. The program generates 815 hits (the same as I get with WordSmith) quite quickly, but not as quickly as WordSmith. It takes AntConc over 10 seconds to generate the results for this search pattern with my corpus of slightly over 1 million words, whereas WordSmith takes only 1 second. Impatient translators carrying out many searches might want the extra speed. The smaller the corpus, the quicker AntConc is to generate results: doing the same search of about half of the Tourism Corpus (= just over 500,000 words) takes just over 5 seconds, and doing the same search of only the Canadian files (= 350,000 words) takes about 3½ seconds.
The concordance lines – or keyword-in-context (KWIC) lines – that are generated with the search pattern are centralised and colour-highlighted. For the purposes of this article, I have made the font-size of the file names and the KWIC results in Figure 3 slightly larger than the default setting in order to make the images more legible. With the smaller font of the default setting, more co-text would be visible to the left and right of the search pattern. Beneath the last KWIC line of the display there is a horizontal bar; by scrolling the horizontal bar to the left and/or right, one can see more of the co-text of the lines. In addition to the KWIC line, the name of the file that each hit derives from is visible. This information is all the translator needs, and in this respect is better than the default display generated by WordSmith, which includes numerous columns containing statistical information that may be useful to the corpus linguist but is of little use to the translator, and which thus reduce the amount of useful co-text on either side of the search pattern. On the other hand, the selected corpus files remain permanently in view on the left, taking up unnecessary screen space; it might be better if the user had the option of hiding these. However this is not really a problem if you expand the size of the display to fill up more, or even all, of your screen, in which case you will see much more context as well as many more KWIC lines; besides, the file list window also includes a progress bar that is useful in showing how the search is progressing.
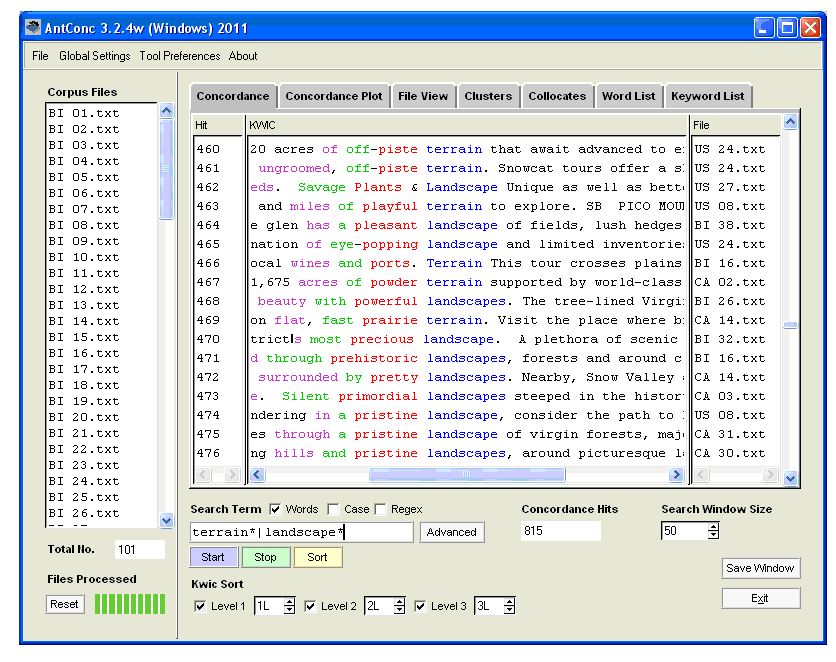
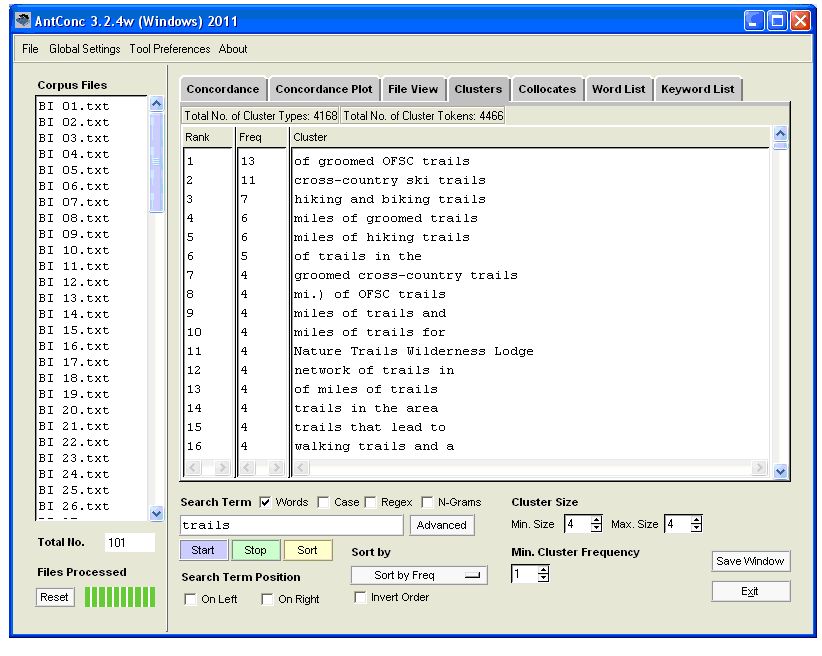
As can be seen in Figure 3, the KWIC lines are by default sorted in file order. In the figure, you can see only hits from files BI 01 – BI 05, but if you scroll down, you can also see hits from BI 06 – BI 37, as well as from the Canadian & US files. Sorting the KWIC lines is straightforward. With the Kwic Sort boxes at the bottom of the display you can, for example, sort collocates alphabetically to the left and right of the search word. In Figure 4, in order to investigate adjectival collocates, the lines have been sorted with 1L as the main sort, 2L as the second sort, and 3L as the third sort. It is also possible to choose the node as the main sort in order to see the hits for landscape* and terrain* separately.
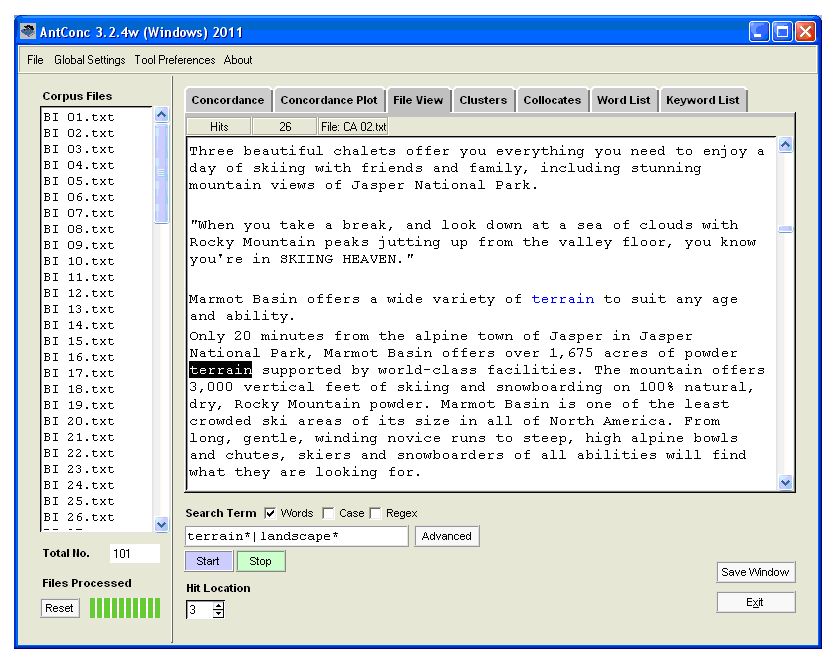
By increasing the figure in the Search Window Size box in the bottom right of the screen, you can increase the amount of co-text that is visible to the left and right of the search pattern when scrolling the horizontal bar to the left or right. However it is also possible to see any concordance line in its full context by clicking on the KWIC node. In Figure 5, the concordance line 467 shown in Figure 4 is displayed in context.
3.6 Affordability A single licence for WordSmith Tools costs £50 (approx €60 / $80 at the exchange rates prevailing on March 1, 2012) plus VAT. Not all translators are able or willing to spend this amount of money, and since other commercially-marketed programs such as MonoConc Pro (Barlow, 2004) seem to sell for a similar price, the only alternative for those on a tight budget is freeware. You can launch AntConc free of charge either from Laurence Anthony’s Website or from the AntConc Homepage. At no point is there any need to acquire a licence. When you click on the link in the browser and select ‘Run’, the program downloads to a temporary space on your hard drive and launches from there. You can of course save the program in a folder of your preference on your hard drive. It is important to remember that if you wish to customise some of the settings to suit your own preferences by creating a settings file as mentioned in Section 3.5, this will not be used automatically at startup unless it is saved in the same folder as the software.
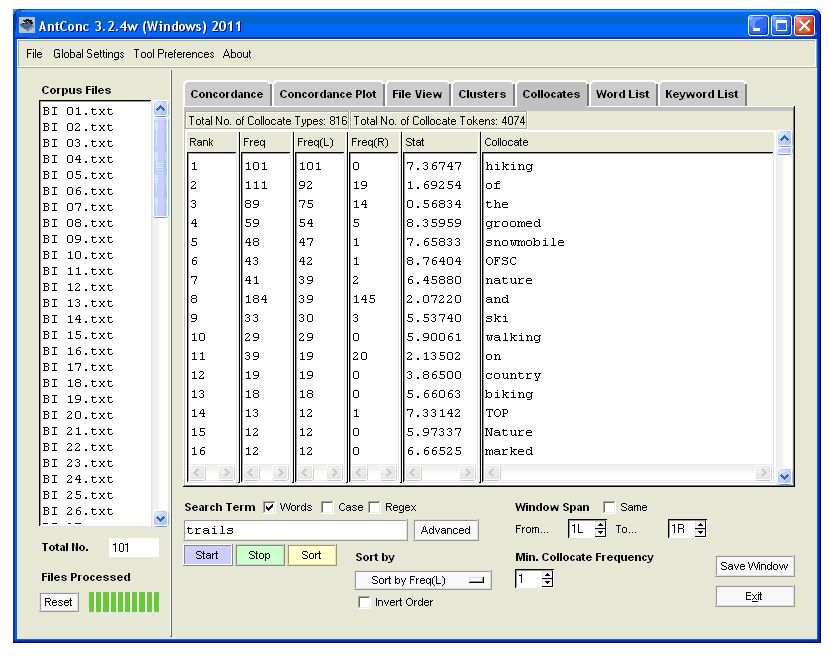
There are some features that, although not mentioned in the list of “must-haves” in Figure 1, would nevertheless be “nice-to-have”, and with some of these I encountered some difficulties, as mentioned in Section 3.1. For example, with the Advanced Search feature you can restrict a concordance search by specifying a context word which must be present within a certain number of words of your search word. (For more about this feature see the section about Advanced Searching in Wilkinson 2007). However I found AntConc to be rather confusing in this respect. For example, it does not allow wildcards to be used with the context word – so if I want to find out if a horse pulls a sled or a sledge or a sleigh, I cannot enter sle* as my context word. Moreover if I add sled, sledge, sleigh as my context words, the program expects ALL of those to be present within the designated context horizon, and I thus get no hits, whereas with WordSmith I would get 22 hits, showing me that the term I am after is horse-drawn sleigh. Another handy “extra” feature for the translator is the collocates display. This can be viewed immediately when using WordSmith’s concordancer, but when using AntConc’s concordancer, the program has to first “jump” to the Word List tool in order to show collocates. So when, after generating a KWIC display of my search for trails, I wanted to view its collocates, it took AntConc about 20 seconds to produce these; however sorting by collocate frequency to left or right was easy and fast.
5. The best freeware corpus analysis program? I have experimented with several other freeware corpus analysis programs but have not yet found any other that comes close to matching AntConc. They tend to have interfaces that are not very intuitive, and consequently I often had difficulties in doing basic things like loading my corpus. In addition some were even tricky to launch, some had very limited sorting options, and some were exceedingly slow. Most had a combination of the aforementioned deficiencies. In many respects AntConc compares very favourably with even the best of the commercial programs available, such as WordSmith and MonoConc Pro. Its main weakness is that it tends to be rather sluggish in generating search results when using corpora of over 1,000,000 words, as mentioned in Section 3.4 and in Section 4. But for those who would like to try out a corpus analysis tool without dipping into their purses or wallets, I would highly recommend AntConc. (Version 3.3.0 is in the pipeline, and due to be released in the spring or summer of 2012). It may be that it more than meets your needs, especially if you are using smaller corpora as translation aids or if you don’t require lightning-fast speed, and especially since nowadays user-friendly freeware is also available (see Wilkinson 2010) that enables you to rapidly compile your own specialized corpora. References Anthony, L. (2011). AntConc (Version 3.2.4). Tokyo, Japan: Waseda University. Available from http://www.antlab.sci.waseda.ac.jp/software.html Barlow, Michael (2004). MonoConc Pro 2.2. Athelstan Publications. Jin, Guangsa (2008). “The comparable corpus-based Chinese-English translation, A case study of city introduction”, in Translation Journal, Volume 12, No 4. Online at: http://translationjournal.net/journal/46corpus.htm Maher, Ailish et al (2008). “Acquiring or enhancing a translation specialism: the monolingual corpus-guided approach”, in The Journal of Specialised Translation, Issue 10, 2008. Online at: http://www.jostrans.org/issue10/art_maher.php Pavlović, Nataša (2007). “Directionality in translation and interpreting practice. Report on a questionnaire survey in Croatia”. Forum 5(2). 79-99. (Also published in Translation Research Projects 1, A. Pym i A. Perekrestenko, eds. Tarragona: Intercultural Studies Group. 79-95.) Online at: http://isg.urv.es/library/papers/PavlovicDirectionality.pdf Scott, Mike (2004). WordSmith Tools version 4, Oxford: Oxford University Press. Scott, Mike (2008). WordSmith Tools version 5, Liverpool: Lexical Analysis Software. Available from http://www.lexically.net/wordsmith/index.html Wilkinson, Michael (2005a). “Using a Specialized Corpus to Improve Translation Quality”, in Translation Journal, Volume 9, No 3. Online at: http://translationjournal.net/journal/33corpus.htm Wilkinson, Michael (2005b). “Discovering Translation Equivalents in a Tourism Corpus by Means of Fuzzy Searching”, in Translation Journal, Volume 9, No 4. Online at: http://translationjournal.net/journal/34corpus.htm Wilkinson, Michael (2007). “Corpora, Serendipity & Advanced Search Techniques”, in The Journal of Specialised Translation, Issue 7, 2007. Online at: http://www.jostrans.org/issue07/art_wilkinson.php Wilkinson, Michael (2010). “Quick Corpora Compiling Using Web as Corpus”, in Translation Journal, Volume 14, No 3. Online at: http://translationjournal.net/journal/53corpus.htm Wilkinson, Michael (2011). “WordSmith Tools: The best corpus analysis program for translators?”, in Translation Journal, Volume 15, No 3. Online at: http://translationjournal.net/journal/57corpus.htm
Thanks to Laurence Anthony for permission to use screenshots from AntConc (version 3.2.4). Published - June 2012
E-mail this article to your colleague! Need more translation jobs? Click here! Translation agencies are welcome to register here - Free! Freelance translators are welcome to register here - Free! |
|
|
Legal Disclaimer Site Map |