|
 |
 |
| Home | More Articles | Join as a Member! | Post Your Job - Free! | All Translation Agencies |
|
|||||||
|
|
Расширенная система согласованных словарей и ее применение для смыслового кодирования и перевода многозначного исходного текста
Универсальное смысловое кодирование Универсальное смысловое кодирование (продолжение) Универсальное смысловое кодирование (приложения)
Содержание: Предпосылки. Сущность предлагаемого метода. Предварительная идентификация исходного текста. Свойства расширенной системы согласованных словарей. Специальные секции дифференцированных (грамматических и синтаксических) значений. Смысловое кодирование исходного текста. Перевод кодированного исходного текста на целевые языки. Некоторые характерные примеры, поясняющие операции смыслового кодирования и перевода. Некоторые соображения общего характера. (примеры кодирования и перевода; фрагменты согласованных словарных статей): 1. Фразы, содержащие многозначные слова. 2. Фразы, содержащие многозначные словосочетания и словосочетания, характеризуемые структурной формулой с переменными лексическими компонентами. 3. Кодирование и перевод с использованием дифференцированных (грамматических) значений глаголов, причастий, деепричастий. 4. Кодирование и перевод с использованием дифференцированных (грамматических) значений местоимений. 5. Кодирование и перевод фраз, обладающих синтаксической неоднозначностью /неполнотой, с использованием дифференцированных (синтаксических) значений. ***** Предпосылки. Как правило, в исходных текстах неизбежно присутствуют многозначные слова и словосочетания. Перевод таких слов и словосочетаний зависит от контекста. Анализ смысла и формы широкого контекста практически невыполним с помощью традиционных программ машинного перевода. В мире публикуется множество исходных текстов, которые необходимо переводить на многие целевые языки. К ним относятся научные статьи, описания изобретений и т.п., которые публикуются в региональных патентных фондах и в национальных научных журналах, но представляют также интерес для иноязычных пользователей. Отсюда следует, что текст на родном языке, который потенциально может быть переведен на многие целевые языки, должен содержать некоторые дополнения к многозначным словам и словосочетаниям, которые указывают универсальным образом на их фактические смысловые значения. Указанные дополнения должны также отражать грамматические (морфологические и синтаксические) особенности более широкого контекста, что при переводе на целевые языки позволит выбрать соответствующие грамматические формы слов или групп слов и синтаксические связи между словами. В целом, подобные смысловые дополнения устраняют как неоднозначность исходного языка, так и взаимные, переводные неоднозначности, что позволит получать корректные по смыслу и по форме машинные переводы на любой из целевых языков. Известны достаточно абстрактные методы смыслового кодирования исходного текста [1–3, 3*]. Один из ранних методов, основанный на семантическом анализе многозначных слов и их смысловом кодировании, описан в US Patent 5,285,386 “Machine translation apparatus having means for translating polysemous words using dominated codes” – “Устройство машинного перевода, содержащее средства для перевода многозначных слов, основанные на доминантных кодах”. Данный метод семантического анализа имеет универсальный характер, т.е. не зависит от того, на какой язык будет осуществляться перевод; в связи с этим предлагаются некоторые коды, имеющие «философский» характер. Этот метод использует четыре разряда классификации, чтобы указать всю информацию о слове: большую (обозначена первой цифрой), среднюю, малую и тонкую классификации. В словаре синонимов все слова классифицируются также в десять больших классификаций, включая "характер/природу", "собственность", "изменение”, "действие", "чувство", "человек", "склонность", "общество", "культура", "предмет". Каждая большая классификация разделяется на десять средних классификаций. В этом воплощении код с символом s имеет следующий вид: S0 принадлежит "характеру/природе" S02 принадлежит "погоде" в "природе" S028 принадлежит "ветру" в "погоде" S028a принадлежит "давлению" в "ветре"…. Данные коды классификации имеют иерархический характер: диапазон значений для верхнего семантического кода является более широким, чем для нижнего семантического кода. Как было отмечено, метод, описанный в этом патенте, может иметь универсальный характер; однако предложенная иерархическая система кодов, характеризующих смысловые значения слов и зависимости между словами, имеет слишком абстрактный характер, т.е. далека от реальных проблем перевода выражений и словосочетаний, отражающих разнообразные способы употребления слов, сложные синтаксические конструкции и т.п. Элементы смыслового кодирования такого же абстрактного характера предлагаются в US Patent 5,523,946 “Compact encoding of multi-lingual translation dictionaries”. Каждое слово это файл, в котором содержится информация, общая для некоторого абстрактного базового языка; эта информация базируется на концепциях типа – часть речи, род, число, знак пунктуации (запятая, круглые скобки,…), область значений, к которым принадлежит данное слово (например, область знаний, действий,…). Например, в код глагола know может быть включён признак (sth), ограничивающий область знаний. Кодирование осуществляет редактор исходного текста. В качестве примера приведена следующая исходная фраза "to have down pat, be an expert"; эта фраза разделяется на следующие символы: "to" "have" "down" "pat" "," "be" "an" "expert". Коды, обозначающие символ и его концепцию, имеют вид: 1991 "to" 872 "have" 501 "down" 18005 "pat" 17 "," 427 "be" 95 "an" 2407 "expert" Тогда вереница (нить), характеризующая эту фразу, приобретает вид последовательности номеров 1991 872 501 18005 17 427 95 2407. Как указано в описании, данный файл перевода состоит из приблизительно 6700 групп концепций. Таким образом, предлагаемый метод содержит элементы смыслового кодирования в виде концепций абстрактного базового языка; однако это кодирование также является очень поверхностным, т.к. не касается конкретных смысловых значений слов, а связано с общими признаками (часть речи, род, область знаний…). Наконец, уже длительное время разрабатывается проект Universal Networking Language (UNL) [3,3*], нацеленный на создание универсального искусственного языка с помощью кодов, которые в некоторой отвлеченной форме учитывали бы множество смысловых и грамматических особенностей исходного языка и, кроме того, отражали бы особенности переводов на множество целевых языков. Иными словами, искусственные смысловые коды должны быть максимально согласованными, т.е. должны одновременно отражать как внутриязыковую многозначность, так и взаимную переводную неоднозначности [16, 16*]. Для этого разработан специальный аппарат записи смысловых значений и словарь UW (universal word), составленный на основе английского языка. Именно при помощи английских слов задаются смысловые и синтаксические ограничения (constraints or restrictions). Текст на UNL - это универсальные слова с дополнительными символами типа: icl (inclusion), означает «вкл., содержит, определяет», aoj - определяет, что объект находится в каком-то состоянии или имеет определенные атрибуты (defines a thing which is in a state or has an attribute): aoj(red (aoj >thing), ball(icl > thing))…ball is red, obj (object) (defines a thing in focus which is directly affected by an event or state), equ (equal), ant (antonym), agt (agent) (defines a thing which initiates an action), bas (basis for expressing degree) defines a thing used as the basis for expressing degree, coo (co-occurrence) defines a co-occurrent event or state for a focused event or state, pos (possessor)
defines possessor of a thing: pos(dog(icl>thing),
John(icl>person)) … John's dog seq (sequence) defines a prior event or state of a focused event or state и многие другие. Каждое значение может иметь также множество частных значений, например: seq (occur, occur) / seq (occur, do) / seq (do, occur) / seq (do, do)
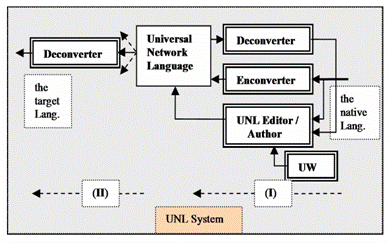
/ seq (occur, (aoj>thing)) ... Примеры обозначений: because Mary arrived, John is happy … agt: 01 (arrive(icl > occur), Mary(icl > person) agt: 02 (happy(icl > do), John(icl > person) rsn(:02, :01); horse … horse (icl > animal) horse (icl >male) horse (icl > apparatus). Коды атрибутов добавляются к универсальному слову и указывают на варианты употребления: категория времени @future, @present, … / число (@sg, @pl / модальность @obligation, @possibility … / характер выражения @emphasis, @focus … @begin-soon, @begin-just… @progress… @complete, @state, @repeat … @generic, @indef … @affirmative, @confirmation, @exclamation, @imperative, @interrogative, @invitation … @probability, @ ability, @expectation, @conclusion и многие другие. Предложение “The dog caught a wild cat” будет иметь следующее UNL-представление: [S] agt(catch(icl>#event).@past.@pred.@entry, dog(icl>animal).@def) obj(catch(icl>#event).@past.@pred.@entry, cat(icl>animal).@indef) mod(cat(icl>animal).@indef,wild(icl>#state, ant>domestic)) [/S] Из примеров следует, что искусственный язык имеет особый словарный состав, особые формы представления смысловых значений, а также собственную морфологию и синтаксис; все эти особенности выражаются в виде сложных цепочек ограничений и атрибутов. UNL основан на двукратном машинном переводе (см. схему): (I) с исходного языка на искусственный язык (UNL Enconventer) и (II) с искусственного языка на целевой язык (UNL Deconventer). На первом этапе автор может в интерактивном режиме вносить изменения непосредственно в текст на искусственном языке с помощью операций прямых и обратных переводов (Author / UNL Editor). Можно указать на следующие свойства системы UNL: а) как было отмечено вначале, анализ смысла и формы широкого контекста практически невыполним с помощью программ автоматического машинного перевода. Предусмотренный в системе UNL двукратный автоматический машинный перевод с использованием промежуточного языка приведет к неизбежному суммированию ошибок в передаче смысла текста и к взаимному влиянию неоднозначностей, возникающих на каждом из этапов; иными словами, ошибки, возникающие на первом этапе, могут порождать цепь ошибок на втором этапе; б) автор имеет возможность вносить некоторые изменения в текст на искусственном языке, как это предусмотрено в системе UNL; но для этого автор должен профессионально владеть этим языком, т.е. должен уметь индицировать с помощью комбинаций символов реальные отклонения, возникшие между исходным текстом и его обратным переводом; в) известно, что операции прямых и обратных переводов выполняются фраза за фразой и требуют многократного повторения; эти операции могут применяться лишь при переводах коротких текстов и могут иметь крайне неустойчивый характер (аналогично замкнутой системе регулирования, содержащей элементы с непредсказуемыми направлениями реакций). Иными словами, если основные программы автоматических машинных переводов (Enconventer, Deconventer) допускают искажения смысла текста, то существенного повышения уровня за счет интерактивного разрешения (Author / UNL Editor) не произойдет; г) из описания UNL неясно с помощью каких символов автор может индицировать в искусственном языке иллюстративные примеры, позволяющие выбрать верную форму употребления слова, словосочетания в переводе на целевой язык; в частности, можно указать на словосочетание “give way”, многозначность которого отражена также и в иллюстративных примерах (с исп. [4,6,7], даны также переводы на русский): give way fail to resist (1) поддаваться; collapse (2) рухнуть; make concessions (3) уступать; (illustrative examples): His health gave ~ Его здоровье (4) надломилось; The bashfulness of the guests soon gave ~ Застенчивость гостей быстро (5) рассеялась; Something gave ~ in him, and words came welling up Что-то (6) прорвалось в нём, и слова… Возможно, система UNL м.б. использована для передачи достаточно коротких и «однозначных» текстов. В целом, можно предположить, что упомянутые выше методы, основанные на искусственных кодах, позволяют решить проблему универсальности, но не содержат элементов, позволяющих повысить точность машинного перевода. Сущность предлагаемого метода. Предварительная идентификация исходного текста. Исходя из общих соображений, многозначность (или неоднозначность) исходного текста, приводящая к неправильным интерпретациям слов и словосочетаний, должна быть устранена до начала автоматического машинного перевода. Информация,
необходимая для предельно точного смыслового кодирования
исходных текстов, уже присутствует в том или ином виде в
толковых и двуязычных словарях. Детальное представление
смысловых значений в толковом словаре характеризует внутреннюю
многозначность исходного языка. Сюда следует отнести и иллюстративные
примеры, отражающие различные формы употребления слова и
словосочетаний при конкретных значениях; при этом переводы
указанных примеров, содержащиеся в двуязычных словарях,
отражают взаимные неоднозначности исходного и целевых языков.
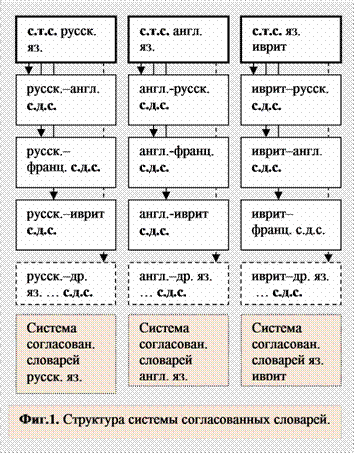
Проблема состоит в том, как превратить элементы словарных статей, включая и упомянутые иллюстративные примеры, в универсальные смысловые коды; иными словами, как согласовать эти элементы с переводами, содержащимися в двуязычных словарях. Указанную проблему предлагается решать с помощью системы согласованных словарей, содержащей опорный толковый словарь родного языка, который мы будем называть далее согласованным толковым словарем (с.т.с.), и специальные словари исходного языка - выходных языков, которые мы будем называть далее согласованными двуязычными словарями (с.д.с.) [19, 19*]. Свойства расширенной системы согласованных словарей. В каждом из согласованных словарей в точности совпадает словарный состав исходного языка и совпадают все элементы словарных статей, включая: - смысловые значения заглавного (производного, составного и т.п.) слова (это касается также и частных значений, на которые разделяются смысловые значения), - все иллюстративные примеры (ил.п.), отражающие использование слова при конкретном смысловом значении, - все словосочетания, их смысловые значения и их собственные ил.п., - грамматические комментарии. Также совпадают последовательности расположения
всех упомянутых элементов и их цифровые, алфавитные, символические
обозначения. Для пояснения ниже представлены фрагменты, характеризующие согласованность словарных статей.
 В с.т.с. исходного языка должны быть объединены функции толкового словаря и словаря перевода. Другими словами, с.т.с. должен отражать также и те элементы исходного языка, которые имеют специальное значение хотя бы в одном из целевых языков, входящих в систему согласованных словарей данного исходного языка. Действительно, если одни случаи неоднозначности не зависят от того, на какой язык переводится текст, то неоднозначности другого типа возникают только при переводе на определенный язык. Таким образом, наряду с множеством смысловых и грамматических особенностей исходного языка, в с.т.с. должны также отражаться особенности переводов на множество целевых языков. Следовательно, словарные статьи должны быть максимально дифференцированными, т.е. должны одновременно отражать не только внутриязыковую многозначность, но и взаимные неоднозначности, а именно: - словарные статьи должны содержать словосочетания нефразеологического характера, имеющие особый (не пословный) перевод хотя бы на один из целевых языков; - словарные статьи должны отражать значения, имеющие морфологическую природу и обусловленные наличием в целевых языках тех или иных отдельных грамматических форм, отсутствующих в исходном языке; с этой целью в словарные статьи вводятся специальные (дополнительные) секции дифференцированных (морфологических) значений; - также словарные статьи должны отражать значения, имеющие синтаксическую природу, т.е. значения, уточняющие возможные синтаксические связи и позволяющие устранить возможную синтаксическую неполноту / неоднозначность в исходном языке; с этой целью в словарные статьи вводятся специальные (дополнительные) секции дифференцированных (синтаксических) значений. В качестве примера, ниже представлен расширенный фрагмент согласованных словарных статей.
Как следует из таблицы, в словарных статьях согласованы и максимально расширены секции иллюстративных примеров и словосочетаний нефразеологического характера, использование которых при смысловом кодировании позволяет верно учитывать особенности употребления слов. Также упомянутые дифференцированные (морфологические) значения представлены в словарных статьях в виде отдельных секций, следующих вслед за теми смысловыми значениями слова, для которых они являются общими. Эти секции имеют условное обозначение (morphm) (от слов morphological meanings) и (syntaxm) (от слов syntax, meanings). Некоторые пояснения, касающиеся секций дифференцированных (морфологических и синтаксических) значений, будут приведены ниже. На Фиг.1 представлена структура систем согласованных словарей.
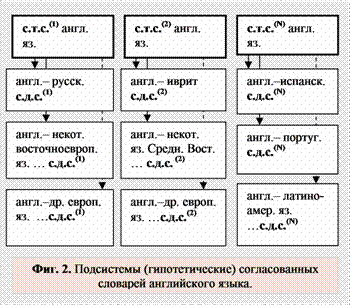
Как было отмечено выше, в системе согласованных словарей наряду с множеством смысловых и грамматических особенностей исходного языка должны также отражаться особенности переводов на множество целевых языков, включая и упомянутые неоднозначности, обусловленные как несовпадением в исходном и в целевых языках ряда грамматических форм слов, так и сложностью в определении некоторых синтаксических связей данного слова с другими членами предложения. Учет всех типов неоднозначностей расширяет объем словарных статей. В связи с этим конкретный исходный язык может иметь несколько подсистем согласованных словарей - для родственных групп целевых языков (Фиг. 2).
В некоторых случаях, подсистема может касаться только двух языков – исходного и целевого; это означает, что единственный в этой подсистеме двуязычный словарь согласован с толковым словарем. Поясним более подробно смысл упомянутых специальных (дополнительных) секций дифференцированных (грамматических и синтаксических) значений. 1. Дифференцированные (морфологические) значения. Речь идет о словах, которые, в зависимости от контекста, выражают различные грамматические признаки, но не имеют в исходном языке соответствующих грамматических форм. В переводе на тот или иной целевой язык этим значениям соответствуют конкретные грамматические формы слова и / или слов, связанных с ним. К таким группах слов могут относиться: 1) личные и возвратные местоимения, которые не имеют в исходном языке некоторых отдельных форм, обозначающих лицо мужского или женского пола / лицо или группу лиц / группу лиц мужского или женского пола / лицо или неодушевлённый предмет, а также притяжательные местоимения, которые не имеют в исходном языке отдельных форм, указывающих на род и / или число принадлежащего объекта, или на род лица, которому это принадлежит (т.е. смысл зависит от того о ком или о чём идёт речь в контексте); в то же время в тех или иных целевых языках для выражения указанных признаков используются местоимения и/или связанные с ними слова, имеющие конкретные грамматические формы; ниже приведены следующие характерные примеры многозначных местоимений в английском и русском языках: - одна и та же форма личных местоимений I, you; я, ты, вы может обозначать как лицо мужского, так и лицо женского рода (также как и падежные
формы me; меня, мне, тебя, тебе ... и возвратные местоимения myself,
yourself;
себя...); кроме того, одна и та же форма личных местоимений you; вы может обозначать как отдельное лицо, так и группу лиц (также как и падежные
формы (to) you; вас, вам ...);
В иврите зависимость личных местоимений от рода и числа субъекта ещё шире, чем в русском и английском языках, в частности, 2-ое лицо имеет дифференцированную форму личных и притяжательных местоимений мужского и женского рода как в единственном, так и во множественном числе; также, в отличие от русского и английского языков, в иврите грамматическая форма глаголов, описывающих действия или состояние субъекта, представленного местоимениями 1-го и 2-го лица, зависит от рода и числа в настоящем времени и т.д. [11]; ниже представлены варианты переводов некоторых местоимений (* - иврит русскими буквами):
Следующий пример касается местоимения you и отражает согласованность словарных статей в тех случаях, когда в одних языках смысловые значения слова определяются контекстом, а в других языках этим значениям соответствуют отдельные формы. В данном случае в английском языке местоимение you заменяет лицо или группу лиц м. рода или ж. рода (что зависит от смысла текста). В переводе на русский язык местоимению you соответствуют две формы – ты, вы, но в переводе на иврит местоимению you соответствуют четыре формы, выражающие м. и ж. род как в ед., так и во мн. числе: אַתֶן / אַתֶם/ אַת/ אַתָה. Как видим, указанные особенности целевых языков отражены в с.т.с. английского языка, в словарной статье которого значение местоимения you представлено в виде четырех частных значений.
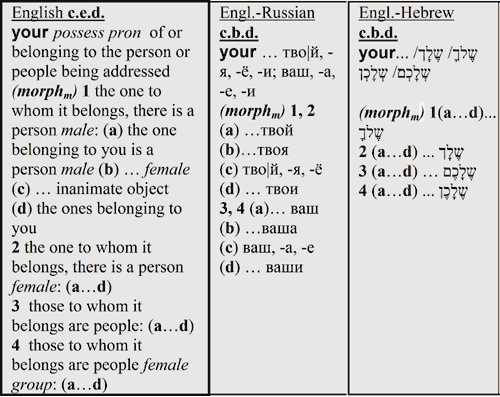
Другой пример касается притяжательного местоимения-существительного yours, которое не имеет каких-л. других грамматических форм, но при этом в сочетании с контекстом может выражать принадлежность объекта мужского или женского или среднего рода или нескольких объектов к лицу или к группе лиц (это играет роль при переводе на русский язык, где местоимению yours соответствуют, в зависимости от контекста, местоимения тво|й, -я, -ё, -и; ваш, -а, -е, -и). Кроме того, имеет значение идёт ли в контексте речь о лице мужского или женского рода или о группе лиц мужского или женского рода, к которому (к которым) выражается принадлежность (это играет роль при переводе на иврит, где местоимению yours соответствуют, в зависимости от контекста, местоимения: שֶלךָ - принадлежит лицу м. рода, שֶלָך - принадлежит лицу ж. рода, שֶלָכֶם - принадлежит группе лиц м. рода, שֶלָכֶן - принадлежит группе лиц ж. рода). Описанная многозначность местоимения yours, имеющая морфологическую природу, отражена в приведенной ниже согласованной словарной статье:
В иврите зависимость личных местоимений от рода и числа субъекта ещё шире, чем в русском и английском языках. 2) глаголы, причастия, деепричастия, которые не имеют в исходном языке некоторых отдельных форм, выражающих однозначно характер действия и/или состояния, достигнутого в результате действия (т.е. о характере действия и/или состояния можно судить лишь в зависимости от контекста); в то же время в тех или иных целевых языках для выражения указанных оттенков действий и / или состояний используются глаголы, причастия, деепричастия, имеющие конкретные грамматические формы; ниже приведены следующие характерные примеры грамматических значений в английском и русском языках: а) в русском языке глагол (в сочетании с контекстом) может выражать одно из следующих значений, которым в английском языке соответствуют отдельные грамматические формы ([12], стр.113-162): - (неопр.) … указывает на то, что глагол несоверш., соверш. вида констатирует факт совершения действия в настоящем, прошедшем, будущем без указания на его длительность, законченность и безотносительно к какому-либо другому действию или моменту (в английском с этой целью используется отдельная группа "неопределённых" времён Indefinite Tenses); - (длит.) … указывает на то, что глагол несоверш. вида выражает длительное действие, которое началось до определенного момента в настоящем, прошедшем, будущем и всё ещё совершается, совершалось, будет совершаться в этот момент, т.е. указывает на действие в процессе его совершения, выражая, таким образом, незаконченное длительное действие (в английском - отдельная группа "длительных" времён Continuous Tenses); - (к опред. м-ту) … указывает на то, что глагол несоверш., соверш. вида выражает действие совершённое (или завершённое, в случае глагола совершенного вида) к определенному моменту в настоящем, прошедшем, будущем (в английском - отдельная группа "совершенных" времён Perfect Tenses); - (изв. дл-ти) … указывает на то, что глагол несоверш. вида выражает длительное действие, начавшееся до определённого момента в настоящем, прошедшем, будущем и длившееся известный период времени, включая этот момент, или длительное действие, продолжавшееся известный период времени и закончившееся непосредственно перед определённым моментом времени в настоящем, прошедшем или будущем (в английском - отдельная группа "совершенных длительных" времён Perfect Continuous); - (состояние), (действие, неопред.), (действие, длит.), (действие, к опред. м-ту) … указывают на то, что глагол совершенного вида выражает в страдательных оборотах результат действия (the existing condition in which an object is), т.е. состояние, или собственно действие (the fact or process of doing) (в английском - отдельная группа времён страдательного залога, [12], стр.166-184); - (в наст.-будущ.), (в прошл.) … указывают на то, что глагол выражает действие (маловероятное) в условном предложении в сослагат. наклонении с частицей бы; время выполнения условия зависит от контекста (м.б. указано как в предшествующем, так и в последующем предложении). Также в русском языке причастие, деепричастие (в сочетании с контекстом) может выражать одно из следующих значений, которым в английском языке соответствуют отдельные грамматические формы ([12], стр.113-162): - (одновр.), (ранее) … указывают в действительных причастных оборотах на действия одновременные или предшествующие действию, выражаемому сказуемым; - (реальн.) … указывает в страдательных причастных оборотах несоверш. вида на реальное действие, выражаемое причастием; - (вообще) … то же, но на действие, происходящее безотносительно ко времени. В следующей таблице представлены дифференцированные (морфологические) значения глагола заканчивать:
б) в английском языке глагол (в сочетании с контекстом) может выражать одно из следующих значений, которым в русском языке соответствуют отдельные грамматические формы ([12]): - (imperf-ve), (perf-ve) … указывают на то, что глагол в Infinitive или в Indefinite Tense, не имея особых грамматических форм несовершенного или совершенного вида, выражает в сочетании с контекстом действие несовершенного или совершенного вида; это следует учитывать при переводе, например, на русский язык, в котором глаголы имеют отдельные формы несовершенного и совершенного вида; - (action) the fact or process of doing, (state) the existing condition in which an object is … указывают на то, что страдательный оборот выражает действие над объектом или состояние объекта, если не отмечается какое-либо другое значение, характеризующее действие, напр., (imperf-ve) или (perf-ve); - (indicative), (subjunctive) … указывают на то, что глагол в Indefinite Infinitive или в Perfect Infinitive в сочетании с глаголом should выражает действие в форме изъявительного или сослагательного наклонения. Также в английском языке причастие (в сочетании с контекстом) может выражать одно из следующих значений, которым в русском языке соответствуют отдельные грамматические формы ([12]. стр. 279-287): - (simult.) … причастный оборот выражает действие, одноврем. с действием сказуемого; - (preced.) … причастный оборот выражает действие, предшеств. действию сказуемого; - (imperf-ve), (perf-ve) … причастный оборот выражает действие несоверш. или соверш. вида. В следующей таблице представлены дифференцированные (морфологические) значения глагола to ask:
3) существительные, которые не имеют в исходном языке форм ед. и мн. числа, в то время как в переводе на те или иные целевые языки они приобретают, в зависимости от контекста, отдельные формы ед. и мн. числа и т.д. Во всех приведенных выше случаях автору достаточно лишь внимательно всмотреться в свой контекст, чтобы внести в дополнение к слову фактическое дифференцированное (морфологическое) значение – это обеспечит верный перевод. 2. Дифференцированные (синтаксические) значения. Также в словарных статьях представлены значения, которые выражают возможные синтаксические связи данного слова с другими словами в предложении; указанные синтаксические связи характеризуют некоторые предикативные (в части сказуемого) и непредикативные (атрибутивные, объектные, обстоятельственные) синтаксические отношения (syntactical relations). Использование дифференцированных (синтаксических) значений при смысловом кодировании позволяет исключить погрешности машинного перевода (syntactical errors) в трактовке таких исходных предложений, которые обладают синтаксической двусмысленностью или синтаксической неполнотой (syntactical ambiguity/ incompleteness), в частности, содержат удаленные или обособленные или удаленно-обособленные пояснительные приложения (атрибутивные, обстоятельственные), внутри которых присутствуют собственные дополнения. Примерами таких приложений могут быть обособленные определения, удаленные от определяемого объекта (существительного, местоимения), обособленные обстоятельства, удаленные от сказуемого (в противоположность однородным членам предложений, которые находятся в одинаковых синтаксических отношениях с одним членом предложения, выполняют одну синтаксическую функцию и объединяются друг с другом путём перечисления или с помощью сочинительных союзов [12*]). Например, в русском языке синтаксические отношения во многих случаях базируются на том, что слова – определения (прилагательные, причастия), обособленные определения, придаточные определительные предложения, именные части составных сказуемых и т.д. имеют грамматические признаки, отражающие род и/или число определяемого слова; в то время как переводы этих слов на те или иные целевые языки могут не иметь указанных признаков, вследствие чего синтаксические отношения целиком зависят от порядка слов. Такие различия в языках могут приводить к синтаксической неопределенности переведенных фраз. Известные программы машинного перевода во многих случаях допускают смысловые неточности при переводе фраз, содержащих синтаксически сложные формы. Дифференцированные (синтаксические) значения представлены в словарных статьях в виде отдельных секций, следующих вслед за теми смысловыми значениями слова, для которых они являются общими. Эти секции, имеющие в словарных статьях условное обозначение (syntaxm) (от слов syntax, meanings), могут касаться синтаксических связей следующих слов: - прилагательное, которое может являться
частью обособленного определения/ приложения к некоторому
контекстному слову (к.с.); В секциях дифференцированных (синтаксических) значений далее приняты следующие обозначения: к.с.* / c.w.* – контекстное слово, которое автор должен отметить в исх. тексте (во всех случаях, касающихся идентификации синтаксических связей слов). Для пояснения приведем характерные примеры словарных статей, содержащих секции (syntaxm):
Т.о., автору также достаточно лишь внимательно всмотреться в свой контекст, чтобы внести в дополнение фактическое дифференцированное (синтаксическое) значение данного слова и отметить соответствующее к.с. – это обеспечит при переводе верную синтаксическую связь между словами в пределах данного предложения (в случае местоимения - отмеченное к.с. может находиться и в одном из предшествующих предложений). Расширенный пример согласованных словарных статей глагола to take был представлен выше. В примерах, приведенных в приложениях к данной статье, представлены различные фрагменты словарных статей. Далее описываются последовательности операций смыслового кодирования и перевода. Смысловое кодирование исходного текста. Данный процесс выполняется в компьютере автора исходного текста с помощью служебной программы, содержащей упомянутый с.т.с. исходного языка. Автор анализирует исходный текст и выделяет очередное слово особым шрифтом в случае, если, по мнению автора (в некоторых случаях – по инициативе служебной программы), данное слово обладает хотя бы одним из следующих признаков: а) данное слово является многозначным словом, причём его сочетание с соседними словами не содержит информации, достаточной для выбора смыслового значения, наиболее близкого к исходному тексту; б) грамматическая форма данного слова и связанных с ним слов не отражает тот или иной оттенок фактического смысла текста, хотя в переводе на те или иные целевые языки данное слово и/или связанные с ним слова могут иметь конкретные грамматические формы, выбор которых строго зависит от контекста (как это следует из приведенных выше примеров дифференцированных (морфологических) значений); в) данное слово вместе с некоторыми соседними словами, возможно, представляет собой словосочетание; для перевода этого словосочетания необходимо осуществить поиск среди известных словосочетаний, относящихся к данному слову, причём, возможно, есть лексические или структурные различия, которые не влияют на иносказательное значение словосочетания, например:
- вклинились определения или обстоятельства к тем или иным
словам, уточняющие значение словосочетания в целом, в связи с этим возникает проблема определить, что некоторые слова принадлежат к сочетанию, найти границы внутри фразы, определить ключевое слово и, наконец, выбрать значение, соответствующее контексту; г) данное слово вместе с некоторыми соседними словами, возможно, представляет собой многозначное словосочетание; д) данное слово имеет несколько родственных семантических значений, которым соответствуют неравнозначные переводы или переводы с неравнозначными формами употребления (по отношению к общей направленности исходного текста или по отношению к характеру действий и обстоятельств). Во многих случаях корректный перевод части фразы или всей фразы может быть получен лишь путём выбора наиболее подходящего ил.п. Использование этого ил.п. при последующем переводе исходной фразы на целевые языки позволяет выбрать верный вариант перевода данного слова, а также отразить особенности использования слова, например, особенности синтаксической структуры, специфической для фраз подобного типа в этом целевом языке, или особенности глагольных форм и т.д. е) данное слово вместе с некоторыми соседними словами, возможно, представляет собой удаленное или обособленное или удаленно-обособленное пояснительное приложение (атрибутивное, обстоятельственное), внутри которого, возможно, присутствуют собственные дополнения. Далее служебная программа выполняет поиск в с.т.с. словарной статьи, соответствующей отмеченному автором слову; затем автор фиксирует смысл этого слова, сопоставляя исходный текст с теми или иными элементами статьи; при этом он выполняет следующие операции: а) в случае, если данное слово вместе с соседними словами совпадает с одним из словосочетаний фразеологического характера (в английском языке это может быть также и фразовый глагол) или соответствует структурной формуле, характеризующей лексическую изменчивость, то автор отмечает конкретное словосочетание или структурную формулу или конкретное смысловое значение, наиболее близкое исходному тексту, или ил.п., в котором употребление сочетания совпадает с исходным текстом, а область употребления соответствует общей направленности текста, характеру описываемых в нём действий и обстоятельств. Указанные элементы автор отмечает и в том случае, когда между сочетанием в исходном тексте и в словаре имеются лексические или структурные различия. Затем автор с помощью служебной программы помещает в виде дополнения к данному слову заглавное слово и само словосочетание, текст смыслового значения или текст иллюстративного примера. При этом автор выделяет в исходном тексте жирным шрифтом данное слово и другие слова, входящие в состав сочетания (за исключением вклинившихся слов), и, кроме того, с помощью специальных граничных символов обозначает левую и правую границы сочетания в предложении (например, угловыми скобками). б) но в случае, если данное слово не принадлежит ни одному из словосочетаний фразеологического характера, то автор отмечает в словарной статье конкретное смысловое значение слова, наиболее близкое исходному тексту, при условии, что грамматические признаки при этом значении, характеризующие изменяемые формы и формы управления другими словами, не противоречат исходному тексту (речь идет о следующих признаках: форма употребления глагола - в соверш./несоверш. виде; управление глагола, в т.ч. предлоги, падежные окончания; форма прямого дополнения и т.п.; форма атрибутивного, предикативного употребления ...); в) если данное слово вместе с соседними словами совпадает с одним из словосочетаний нефразеологического характера, приведенных в словарной статье при этом значении, то автор отмечает это словосочетание; затем автор выделяет слова в исходном тексте особым шрифтом и граничными символами, как это описано выше; г) если же данное слово не фигурирует ни в одном из словосочетаний, но в группе иллюстративных примеров при этом значении содержится конкретный пример с аналогичным употреблением слова, а область применения соответствует общей направленности текста, характеру описываемых в нём действий и обстоятельств, то автор отмечает этот пример; д) если в словарной статье имеется упомянутая выше секция дифференцированных (морфологических) значений (morphm), то автор отмечает конкретное значение слова, касающееся рода и/или числа, лица или неодушевлённого предмета, характера действия или состояния, и т.д. и т.п.; в случае, если необходимо идентифицировать конкретное местоимение, то автор отмечает также к.с., которое заменяет это местоимение; е) наконец, если в словарной статье имеется упомянутая выше секция дифференцированных (синтаксических) значений (syntaxm), то автор отмечает конкретное значение слова, указывающее на то, что оно входит в состав неглавного члена предложения, обособленного/ удалённого от того к.с., с которым оно синтаксически связано, и отмечает это к.с. В
некоторых случаях автор отмечает конкретный ил.п. в
словарной статье, касающейся одного из соседних слов, связанных
с данным словом, при условии, что указанный ил.п.
соответствует смысловому значению и другим признакам,
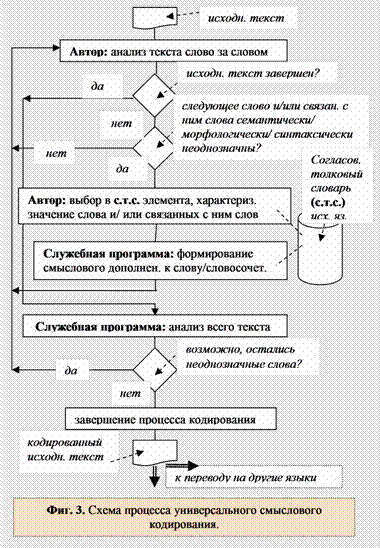
упомянутым выше. Затем служебная программа переносит из словарной статьи в исходный текст заглавное слово и те элементы, которые отмечены, помещая всё в виде смыслового дополнения к данному слову; в тех случаях, когда отмечено к.с., то служебная программа помещает это слово в дополнение (или подсчитывает порядковый номер этого слова в данном предложении и помещает этот номер в дополнение). Если же отмечена некоторая группа контекстных слов, то программа помещает в дополнение эту группу слов. Затем автор отмечает в исходном тексте следующее слово, обладающее одним из описанных выше признаков, и т.д. – до конца текста. В завершение выполняют запись полученного текста, готового к переводу на другие языки. Схема, отражающая процесс универсального смыслового кодирования, представлена на Фиг. 3.
далее: см. Продолжение Ссылки (References). специальные источники: 1. US Patent 5,285,386 Machine translation apparatus having means for translating
polysemous words using другие источники: 4. Кунин А. В. (1967),
Англо-русский фразеологический словарь, Советская энциклопедия, М., 1233 – 1264 03.09.08. Владимир Коэн-Цедек, преподаватель иврита, соавтор сайта "Иврит через мозг", соведущий еженедельной консультации по ивриту на радио Река. "Vladimir Katsman (Cohen-Tzedek)" <vcohen@mail.ru>
Panich Iuli Research Institute of Automation, Leningrad, head of laboratory
– senior researcher. Fields of interest: New Fields of interest: Publications: He can be reached at: Published - July 2008 See also: "Experience of preliminary identification and translation of the text's fragments with use of the system of coordinated dictionaries" by Panich Iuli
E-mail this article to your colleague! Need more translation jobs? Click here! Translation agencies are welcome to register here - Free! Freelance translators are welcome to register here - Free! |
|
|
Legal Disclaimer Site Map |