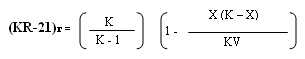|
 |
 |
| Home | More Articles | Join as a Member! | Post Your Job - Free! | All Translation Agencies |
|
|||||||
|
|
How to Test a Test: Preliminary Procedures & Objective Scrutiny of a Test
1. Preview
To more precisely handle the issue, it is better to start with the belief that the question “how to test a test” is nothing separate from adopting particular strategic steps while developing a test so as to improve its usefulness and efficiency. Thus, technically speaking, testing a testcan be better understood by considering it as a major and yet prominent phase of test production or development. Test designer adopts step-by-step strategies to develop a useful and appropriate test. In doing so, one step will be to test the usefulness and efficiency of a test. Therefore, testing a testrefers to any procedures/strategies/techniques utilized to test, or in fact analyze, the efficiency and value of a test. In order to conduct the research in a more organized manner and take best advantage of practical strategies for testing a test, the investigator divides the paper into two major sections. The first part deals with preliminary proceduresand the second section presents anobjective analysis of a test (pretesting). 2. Preliminary procedures 2.1 Test specification (test blueprint) Test specification refers to systematic examination of content areas, topics, course syllabi and textbooks that then inevitably demands to trace its realization(s) in a test. To examine a test more critically, it needs to keep track of two important elements in a test, i.e. functionand content. 2.1.1 Function specification In order to examine the function of a test, three factors should be taken into account: characteristics of the examinees, the specific purpose of the test, the scope of the test.
In addition to the aforementioned factors, the educational system through which the language users have carried out their education should be taken into consideration, because the educational policy affects on the mastery level of examinees at different language skills.
2.1.2 Content specification To determine the content of a test, the primary step is to examine the instructional objectives. It is recommended to provide an outlined list of major topics and points covered within a course (table of specifications) in advance. The main purpose of the table of specifications is to assure the test developer that the test includes a representative sample of the materials covered during a particular course. 2.2 Reviewing In this stage, the written items need to be reviewed with respect to the accuracy and appropriateness of content. This can be done either by the very test constructor or by an outsider. Through the reviewing stage, problems unnoticed by the test developer will most likely be observed by the reviewers. The reviewer would suggest modifications in order to alleviate the problems. This stage includes the following components:
The preliminary mentioned procedures indirectly assist and pave the ground for the next significant stage, i.e. objective scrutiny of a test(pretesting), because the modified and improved items would make pretesting more fruitful. 3. Objective scrutiny of a test (pretesting) Even after careful moderation (reviewing), there are likely to be some problems with every test. The aim in this stage is to administer the test first to an adequate number of subjects as similar as possible to those for whom it is really intended (i.e. target population). In other words, pretestingis defined as administering the newly developed test to a group of examinees with characteristics similar to those of the target group. This try-out activity of pretesting involves administering the test for the purpose of collecting information about the usefulness of the test itself, and for the improvement of the test and testing procedures. Specifically speaking, the goal of pretesting will be twofold. The first purpose is to determine objectively the characteristics of the individual items (item analysis). These characteristics include item facility(IF), item discrimination(ID) and choice distribution(CD). The second purpose of pretesting, which is called validation, is to determine the characteristics of the items altogether. These characteristics include reliability, validityand practicality. 3.1 Individual item analysis 3.1.1 Item facility (IF) [facility value, item easiness, item difficulty] It refers to a measure of the ease of a test item. Item facilityhas to do with how easy or difficult an item is from the viewpoint of the group of students or examinees taking the test of which that item is a part. The reason for concern with IF is very simple; a test item that is too easy (say, an item that every student answers correctly) or a test item that is too difficult (one, say, that every student answers incorrectly) can tell us nothing about the differences in ability with the test population; so it should be deleted. A formula for producing decimal value for IF:
Item with facility indexes beyond 0.63 are too easy, and items with facility indexes below 0.37 are too difficult; thus it should be deleted. Item facility refers to the proportion of correct responses, while item difficulty refers to the proportion of wrong responses. Item difficulty = 1 – item facility 3.1.2 Item discrimination (item differentiation) It refers to the notion that how well a test item discriminates between weak (less knowledgeable) and strong (more knowledgeable) examinees in the ability being tested. There is a relationship between item facility and item discrimination. An item with a too high or low facility index is not likely to have a discrimination power. A suitable procedure for calculating ID is to rank the total scores of test takers from the highest to the lowest. Then, dividing examinees into two equal groups (the higher half (high group/H) and lower half (low group/L). At last, apply this formula:
CH: number of correct responses to a particular item by the examinee in the high group CL: number of correct responses to a particular item by the examinee in the low group In contrast to item facility where the ideal index is 0.50, for item discrimination the ideal index is unity (1). Nevertheless, items which show discrimination value beyond 0.40 can be considered acceptable. An item discriminates in a positive direction (positive discrimination) if more test takers in the upper group than the lower group get the item right. 3.1.3 Choice distribution (CD) [response frequency distribution) Item facility and item discrimination are the two determining parameters for the acceptability of an item. But choice distribution is a technique which helps a test developer to know how each and all of distractors perform in a given test administration. In simple words, choice distribution refers to the frequency with which alternatives are selected by the examinees [the distribution of responses given to different alternatives in a multiple-choice item]. Choice distribution should be determined in order to improve the test both quantitatively and qualitatively. Thus through choice distribution, the test developer can observe deficiencies existing in the nature of choices and then discard or modify them. For example, if a choice is not selected by any examinees, it implies that this distractor does not function satisfactorily; therefore it should be deleted. 3.2 Overall test analysis 3.2.1 Reliability A quality of test scores which refers to the consistency of measures across different times, test forms, raters and other characteristics of the measurement context. Synonyms for reliability are: dependability, stability, consistency, predictability and accuracy. To put another way, the tendency toward consistency from one set of measurement to the next is called reliability. In doing so, reliability is best defined as the consistency of scores produced by a given test. Methods of estimating reliability:
Although the test-retest method provides a logical estimate of test score reliability, it has some disadvantages as follows: 1 - Arranging and preparing similar conditions under which two administrations take place are obviously difficult. 2 - Human beings are intelligent and dynamic creatures. The longer the interval, the more change will occur in the testees’ behavior, but less memory factor will exist; the shorter the interval, the less change will occur in the testees’ behavior, but more memory factor will exist [two weeks interval is recommended as appropriate]. 3 - There is a test effect, especially when the interval is short. On the second administration, due to the fact that either they have learned something from the test administration before or they have memorized some of the items from the first administration, they may perform differently.
In practice, although we virtually never have strictly parallel tests, we treat two tests as if they were parallel if the differences between their means and variances are not statistically significant.
The relationship among the items will be a sort of reliability of scores regarding their internal relationship (internal homogeneity among the items). That is why this method is sometimes referred to as the internal consistency of the test scores. The test is split, or divided, into two equal halves. The correlation between the two halves is an estimate of the test score reliability. To estimate the reliability of the total test, the formula known as Spearman Brown Prophecy Formula should be used:
This method is more practical and single administration of a single test will also suffice.
K: the number of the items
in a test Summarizing different methods of estimating reliability:
3.2.2 Validity In simple words, validity refers to the extent to which a test measures what it is supposed to measure. Technically speaking, validity is the extent to which the inferences or decisions we make on the basis of test scores are meaningful, appropriate and useful.
The following are guidelines for establishing content validity: 1 - The behavior domain to be tested must be systematically analyzed to make certain that all major aspects are covered by the test items; and in the correct proportions. 2 - The domain under construction should be fully described in advance rather than being defined after the test has been prepared. 3 - Content validity depends on the relevance of the individual’s test response to the behavior areas under consideration, rather than on the apparent relevance of item content.
3.2.3 Practicality This characteristic refers to the usability and practicality of a test. Practically refers to ease of administration (such as clarity and simplicity of directions; convenient time limit), ease of scoring (preferably objective and simple scoring), ease of interpretation and application of a test. 4. Conclusion In conclusion, it is worth mentioning that “testing a test” or “how to test a test” can be technically taken as one of the prominent procedures utilized to examine and yet develop a useful test so as to make it more reliable, valid and practical. Preliminary procedures and strategies for objective scrutiny of a test were rather fully discussed. Now, in order to wrap up the research, the investigator intends to shift the perspective away from the existing discussed framework and consider the notion of testing a test from a different perspective. Although, this novel view, i.e. testing the usefulness of a test, overlaps with and has so much in common with the previously mentioned issues and concepts, it adds some new dimensions to the current framework to make the activity richer. In sum, test usefulness includes six qualities that can be expressed as in the following figure:
Test usefulness can be described as (and also examined in terms of) several different qualities (above ones), all of which contribute in unique but interrelated ways to the overall usefulness of a given test. Usefulness cannot be evaluated in the abstract, for all tests. Evaluating the overall test usefulness of a given test is essentially subjective, since this involves value judgment on the part of the test developer. References: Bachman, L.F.1990. Fundamental Considerations in Language Testing. Oxford: O.U.P. Mousavi, A. 1999. A Dictionary of Language Testing. Tehran: Rahnama Publications. Farhady, H., A. Jafarpur, & P. Birjandi. 1994. Testing Language Skills: from Theory to Practice. Tehran: SAMT Publication
E-mail this article to your colleague! Need more translation jobs? Click here! Translation agencies are welcome to register here - Free! Freelance translators are welcome to register here - Free! |
|
|
Legal Disclaimer Site Map |
 On
initial appearance, the question may seem blurred and rather
complex, but if one takes a systematic and deep look at
it, s/he definitely finds out what it actually means. Due
to typical definition of a test, i.e. in general,
any procedure used to measure a factor or assess some ability;
it might appear possible to find at least a clear answer
indicating the scope of the question. Accordingly, some
specific and classified procedures are required to be applied
so as to put a test in test.
On
initial appearance, the question may seem blurred and rather
complex, but if one takes a systematic and deep look at
it, s/he definitely finds out what it actually means. Due
to typical definition of a test, i.e. in general,
any procedure used to measure a factor or assess some ability;
it might appear possible to find at least a clear answer
indicating the scope of the question. Accordingly, some
specific and classified procedures are required to be applied
so as to put a test in test.