 |
 |
 |
| Home | More Articles | Join as a Member! | Post Your Job - Free! | All Translation Agencies |
|
|||||||
|
|
Translation Technology Failures and Future
The answer is simple. Software developers in the translation industry failed to follow some simple rules: Rule 1:Never have the computer do anything unless it can do it BETTER and FASTER than a human. (Faster is not enough, it has to improve quality as well.) Rule 2:Marry the technology with the human. Have the computer do what it does best and let the human do what they do best. Rule 3:Keep it simple. (Complicated software is useless). Rule 4:Adapt the software to work with the human, don't try to adapt the human to work with the software. For example, accounting software developers have NOT tried to replace accountants with artificial intelligence. They built their software to help the profession, not replace it. Accounting software was designed to augment an accountant's work. The computer takes care of the time consuming tedious tasks (things a computer can do faster and better) and lets the human make the accounting decisions. They even designed the user interface to look like what an accountant was familiar with; filling out a check on the screen, logging information into a ledger, etc. The average person on the street believes computers will replace translators someday, but they don't believe accountants will be replaced. Yet in reality it would be easier to replace all the accountants in the world with artificial intelligence software than it would be to replace all the translators. After all computers handle numbers much easier than languages. Accounting also has set rules and regulations established by GAAP, FASB, the FCC and other regulatory bodies that lend themselves to automation in decision making. The problem is linguistics is not an exact science and languages don't always follow the rules. All grammars leak and all dictionaries are incomplete. Words can be put together in ways that cause the individual semantic meaning of each word to be changed to something different when the words are combined. If that weren't true then the slogan "Nothing sucks like an Electrolux" would be a very catchy way to describe the power of Electrolux vacuum cleaners. MT and CAT toolsFor 30 years, software developers have been trying to replace human translators with machine translation. This is a direct violation of rules 1 and 2 above. I believe this legacy has caused our industry to fall behind in performance improvements made in other industries. After all if most people believe you can replace the translator with software, why spend money trying to build software to help the translator. Since machine translation didn't work developers turned to Computer Aided Translation (CAT) tools. By definition, CAT tools are a marriage of machine translation and human translation. But this marriage wasn't the kind of marriage where the computer did what it did best and the translator did what he or she did best. The software developers said we have the computer doing a pretty good job with some decisions; we just need the translator to make it better. It was a marriage of convenience where the translator was relegated to being a housewife that had to clean up the messes made by the computer. As a result, most translators in the world don't use any of these systems and prefer to work with a word processor alone. Until we can build tools that the profession feels they can't live without, we won't see the kinds of improvements other professions enjoy. Redundancy and Translation MemoryPierre Isabelle stated that "existing translations contain more solutions to more translation problems than any other available resource." Pierre was alluding to the fact that if a previous translation already provided an appropriate way to translate a word, phrase, or expression in context then the translator could readily reuse that translation. They wouldn't need to recreate the translation anew. Translation Memory (TM) tools have shown the most progress in increasing performance. The broad definition of TM is reusable translations. In a narrow sense this means reusable sentences since most TM tools parse the document up into sentences and keep the sentence pairs in a database. Sentences proliferate, i.e. they grow in number every day. Even if we keep huge databases of previously translated sentences the translator will constantly be encountering new sentences not previously formed or translated. Sure there are times when a translator is translating a manual or a document that has a lot of repeat sentences. In these situations these tools are very helpful. But what value is the tool if a translator is translating a new document that has no sentences even remotely related to its TM. The translator is left to his or her own devices. What if we could provide a translator with reusable translations below the sentence level? Words in context and parts of sentences can also be leveraged to allow a translator to use their TM tool even when the sentences are not the same or even close. The solution is to index the words in TM instead of sentences and have the search engines find exact matches, and natural language matches of sub sentences in addition to full sentences and paragraphs. Since the search engine in most current TM systems tries to find only an exact match or fuzzy match of whole sentences they don't lend themselves to finding matches that are parts of sentences, like words and phrases nor can they go above the sentence level to leverage paragraphs. The value of "reusable translations" below and above the sentence level can best be illustrated in the following graph: 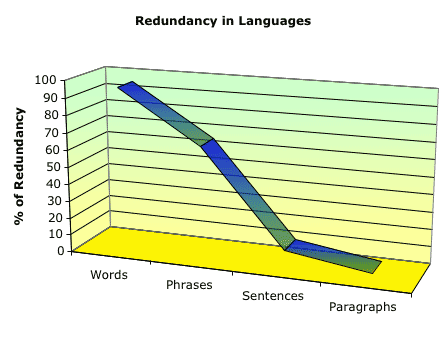
As the graph illustrates, words are the most redundant aspect of languages and paragraphs are the least redundant. Phrases or parts of sentences are more redundant than sentences. Current translation memory tools provide some benefit. They are very useful in environments where the sentences of your previous translations are very close to the sentences in your next translation. Because this accounts for about 5% of the translation work done in the world most TM tools leave the translator wanting more. What is needed is a new design approach that leverages the words and phrases of existing translations in context, but still allows the translator to reuse sentences and paragraphs as well. Translation Support SoftwareA new design theory is emerging. It is called Translation Support Software (TSS). Its purpose is to augment the work of translators and is based on the rules stated at the beginning of this article. A few systems have been designed on these premises. RALI's TransSearch system from the University of Montreal and Translator's Intuition from TermSeek allow translators to access translation memory at the word, phrase, partial sentence, sentence, and paragraph level. While other translation memory programs help a translator 5% of the time, these programs provide help to translators on almost every sentence they translate. The reason these systems can provide more reusable translations is because they were designed differently. In these systems the whole document is kept together and not parsed down to the sentence level. The translation segment is the paragraph not a sentence. Now you might assume if the translation segments were whole paragraphs their search engine would be limited to finding only whole paragraphs or fuzzy matches of them. That's not the case. Instead of having an automatic search of the TM database to find whole translation segments (i.e. sentences in other TM systems) these new systems actually index every word in context. There is no automatic search to find reusable translations. They let the translator decide what they want to find. This puts the translator in control. In the TransSearch system the translator just types in the word or phrase they wish to find and they see equivalent translations in context. In Translator's Intuition the translator uses "Selected Search" to select the words or phrases in the source text of the document they are translating and it displays all reusable translations. In both of these systems you can either type or select whole sentences and paragraphs to leverage translation memory at the same level as other translation memory systems. The reason these systems can provide higher productivity rates is because they have not violated any of the rules. The translator stays in control and the computer does his or her bidding. The computer doesn't provide "fuzzy" matches that may or may not be helpful, but exact matches of the same words in the same order in context. Likewise both TransSearch and Translator's Intuition provide natural language searches. Natural language search engines take into account conjugation, plural, agreement and many other syntactic elements in their searches. This method of development is more difficult to program, but it allows the translators to find sentences or phrases that may have the same semantic meaning even though the differences in the sentences or phrase is statistically quite different. Statistical differences is what most TM systems use in their "fuzzy matching." They basically look at the number of characters that are different between two sentences and provide the translator with the sentence that has the lowest number of different characters. For example, Elliott Macklovitch and Graham Russell in What's been Forgotten in Translation Memory pointed out that statistical based TM systems would say that sentence (1) below is closest to sentence (2) even though sentence (3) is closer in meaning.
Sentence (1) differs from sentence (2) by only 4 characters, while sentence (3) differs from sentence (1) by 9 characters. A system that employs natural language processing in its matching would find sentence (3) to be closer to sentence (1). Ergonomics in Software DesignRules 3 and 4 deal with the ergonomics of software design. Most of the TM systems that have been built have approached translation technology from a workbench approach. They have designed multiple tools to do different jobs. This has occurred as a matter of necessity. It costs millions of dollars to build your own word processor, and database tool from scratch. Since most of the money invested in our industry has been in machine translation these developers did the best they could with what they had to work with. We have to commend those who have managed to build TM systems from Access databases and with Visual Basic macros attached to Microsoft Word. It is actually amazing what they have accomplished considering what they had to work with. Other professional software packages though do not employ multiple tools to serve the professionals. Typically they need only choose one computer aided design software package or one accounting package to do their job. Multiple tools add complexity. There may be some benefit in using software we are familiar with like Microsoft Word, but this familiarity could be built into a new system just as well. Before we see the performance gains attained in other industries software developers in our industry need to build comprehensive tools that simplify the translation process. Translation tools of the future will need to handle terminology management, translation memory, word processing, desktop publishing, filtering of content in and out of various platforms, natural language processing, project management, team translation functions, database management and global content management all in one software package. Two things need to happen before the translation industry realizes the gains experienced by other industries. First, our approach to designing software has to change. Second, we need to start treating translators like the professionals they are and build systems to help them not replace them. Timothy R. Hunt is CEO of TermSeek Inc., developers of Translator's Intuition™, a new design in translation support software. Mr. Hunt has 22 years experience in the translation industry and has worked with translation teams in 65 languages in more than two-dozen countries. He has a BA in Asian Studies and an MBA.
Reprinted
by permission from the Globalization Insider,
25 February 2003, Volume XII, Issue 1.4. Copyright the Localization Industry Standards Association (Globalization Insider: www.localization.org, LISA: www.lisa.org) and S.M.P. Marketing Sarl (SMP) 2004
E-mail this article to your colleague! Need more translation jobs? Click here! Translation agencies are welcome to register here - Free! Freelance translators are welcome to register here - Free! |
|
|
Legal Disclaimer Site Map |
 Because of improvements in technology designers,
graphic artists, accountants and many other professionals
can accomplish in an hour what used to take them
a day. In other words, technology has improved their
performance by as much as 800% and it has improved
the quality of their work at the same time.
Because of improvements in technology designers,
graphic artists, accountants and many other professionals
can accomplish in an hour what used to take them
a day. In other words, technology has improved their
performance by as much as 800% and it has improved
the quality of their work at the same time. 
