|
 |
 |
| Home | More Articles | Join as a Member! | Post Your Job - Free! | All Translation Agencies |
|
|||||||
|
|
Wikipedia about machine translation
Machine translation From Wikipedia, the free encyclopedia Machine translation, sometimes referred to by the abbreviation MT, is a sub-field of computational linguistics that investigates the use of computer software to translate text or speech from one natural language to another. At its basic level, MT performs simple substitution of words in one natural language for words in another. Using corpus techniques, more complex translations may be attempted, allowing for better handling of differences in linguistic typology, phrase recognition, and translation of idioms, as well as the isolation of anomalies. Current machine translation software often allows for customisation by domain or profession (such as weather reports) — improving output by limiting the scope of allowable substitutions. This technique is particularly effective in domains where formal or formulaic language is used. It follows then that machine translation of government and legal documents more readily produces usable output than conversation or less standardised text. Improved output quality can also be achieved by human intervention: for example, some systems are able to translate more accurately if the user has unambiguously identified which words in the text are names. With the assistance of these techniques, MT has proven useful as a tool to assist human translators, and in some cases can even produce output that can be used "as is". However, current systems are unable to produce output of the same quality as a human translator, particularly where the text to be translated uses casual language. History Main article: History of machine translation The history of machine translation begins in the 1950s, after World War II. The Georgetown experiment (1954) involved fully-automatic translation of over sixty Russian sentences into English. The experiment was a great success and ushered in an era of substantial funding for machine-translation research. The authors claimed that within three to five years, machine translation would be a solved problem. Real progress was much slower, however, and after the ALPAC report (1966), which found that the ten-year-long research had failed to fulfill expectations, funding was greatly reduced. Beginning in the late 1980s, as computational power increased and became less expensive, more interest was shown in statistical models for machine translation. The idea of using digital computers for translation of natural languages was proposed as early as 1946 by A.D.Booth and possibly others. The Georgetown experiment was by no means the first such application, and a demonstration was made in 1954 on the APEXC machine at Birkbeck College (London Univ.) of a rudimentary translation of English into French. Several papers on the topic were published at the time, and even articles in popular journals (see for example Wireless World, Sept. 1955, Cleave and Zacharov). A similar application, also pioneered at Birkbeck College at the time, was reading and composing Braille texts by computer. Recently, Internet has emerged as global information infrastructure, revolutionizing access to any information, as well as fast information transfer and exchange. Using Internet and e-mail technology, people need to communicate rapidly over long distances across continent boundaries. Not all of these Internet users, however, can use their own language for global communication to different people with different languages. Therefore, using machine translation software, people can possibly communicate and contact one to another around the world in their own mother tongue, in the near future. Translation process Main article: Translation process The translation process may be stated as:
Behind this ostensibly simple procedure lies a complex cognitive operation. To decode the meaning of the source text in its entirety, the translator must interpret and analyse all the features of the text, a process that requires in-depth knowledge of the grammar, semantics, syntax, idioms, etc., of the source language, as well as the culture of its speakers. The translator needs the same in-depth knowledge to re-encode the meaning in the target language. Therein lies the challenge in machine translation: how to program a computer that will "understand" a text as a person does, and that will "create" a new text in the target language that "sounds" as if it has been written by a person. This problem may be approached in a number of ways. Approaches
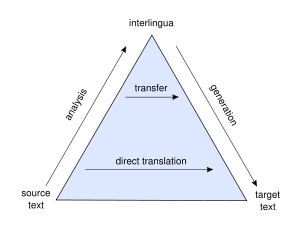
Machine translation can use a method based on linguistic rules, which means that words will be translated in a linguistic way — the most suitable (orally speaking) words of the target language will replace the ones in the source language. It is often argued that the success of machine translation requires the problem of natural language understanding to be solved first. Generally, rule-based methods parse a text, usually creating an intermediary, symbolic representation, from which the text in the target language is generated. According to the nature of the intermediary representation, an approach is described as interlingual machine translation or transfer-based machine translation. These methods require extensive lexicons with morphological, syntactic, and semantic information, and large sets of rules. Given enough data, machine translation programs often work well enough for a native speaker of one language to get the approximate meaning of what is written by the other native speaker. The difficulty is getting enough data of the right kind to support the particular method. For example, the large multilingual corpus of data needed for statistical methods to work is not necessary for the grammar-based methods. But then, the grammar methods need a skilled linguist to carefully design the grammar that they use. To translate between closely related languages, a technique referred to as shallow-transfer machine translation may be used. Rule-based The rule-based machine translation paradigm includes transfer-based machine translation, interlingual machine translation and dictionary-based machine translation paradigms. Main article: Rule-based machine translation Transfer-based machine translation Main article: Transfer-based machine translation Interlingual Main article: Interlingual machine translation Interlingual machine translation is one instance of rule-based machine-translation approaches. In this approach, the source language, i.e. the text to be translated, is transformed into an interlingual, i.e. source-/target-language-independent representation. The target language is then generated out of the interlingua. Dictionary-based Main article: Dictionary-based machine translation Machine translation can use a method based on dictionary entries, which means that the words will be translated as they are by a dictionary. Statistical Main article: Statistical machine translation Statistical machine translation tries to generate translations using statistical methods based on bilingual text corpora, such as the Canadian Hansard corpus, the English-French record of the Canadian parliament and EUROPARL, the record of the European Parliament. Where such corpora are available, impressive results can be achieved translating texts of a similar kind, but such corpora are still very rare. The first statistical machine translation software was CANDIDE from IBM. Google used SYSTRAN for several years, but has switched to a statistical translation method in October 2007. Recently, they improved their translation capabilities by inputting approximately 200 billion words from United Nations materials to train their system. Accuracy of the translation has improved. Example-based Main article: Example-based machine translation Example-based machine translation (EBMT) approach is often characterised by its use of a bilingual corpus as its main knowledge base, at run-time. It is essentially a translation by analogy and can be viewed as an implementation of case-based reasoning approach of machine learning. Major issues Disambiguation Main article: Word sense disambiguation Word sense disambiguation concerns finding a suitable translation when a word can have more than one meaning. The problem was first raised in the 1950s by Yehoshua Bar-Hillel. He pointed out that without a "universal encyclopedia", a machine would never be able to distinguish between the two meanings of a word. Today there are numerous approaches designed to overcome this problem. They can be approximately divided into "shallow" approaches and "deep" approaches. Shallow approaches assume no knowledge of the text. They simply apply statistical methods to the words surrounding the ambiguous word. Deep approaches presume a comprehensive knowledge of the word. So far, shallow approaches have been more successful. Named entities Related to named entity recognition in information extraction. Applications There are now many software programs for translating natural language, several of them online, such as the SYSTRAN system which powers both Google translate and AltaVista's Babel Fish as well as Promt that powers online translation services at Voila.fr and Orange.fr. Although no system provides the holy grail of "fully automatic high quality machine translation" (FAHQMT), many systems produce reasonable output. Despite their inherent limitations, MT programs are used around the world. Probably the largest institutional user is the European Commission. Toggletext uses a transfer-based system (known as Kataku) to translate between English and Indonesian. Google has claimed that promising results were obtained using a proprietary statistical machine translation engine. The statistical translation engine used in the Google language tools for Arabic <-> English and Chinese <-> English has an overall score of 0.4281 over the runner-up IBM's BLEU-4 score of 0.3954 (Summer 2006) in tests conducted by the National Institute for Standards and Technology. Uwe Muegge has implemented a demo website that uses a controlled language in combination with the Google tool to produce fully automatic, high-quality machine translations of his English, German, and French web sites. With the recent focus on terrorism, the military sources in the United States have been investing significant amounts of money in natural language engineering. In-Q-Tel (a venture capital fund, largely funded by the US Intelligence Community, to stimulate new technologies through private sector entrepreneurs) brought up companies like Language Weaver. Currently the military community is interested in translation and processing of languages like Arabic, Pashto, and Dari.[citation needed] Information Processing Technology Office in DARPA hosts programs like TIDES and Babylon Translator. US Air Force has awarded a $1 million contract to develop a language translation technology. Evaluation Main article: Evaluation of machine translation There are various means for evaluating the performance of machine-translation systems. The oldest is the use of human judges to assess a translation's quality. Even though human evaluation is time-consuming, it is still the most reliable way to compare different systems such as rule-based and statistical systems. Automated means of evaluation include BLEU, NIST and METEOR. Relying exclusively on machine translation ignores that communication in human language is context-embedded, and that it takes a human to adequately comprehend the context of the original text. Even purely human-generated translations are prone to error. Therefore, to ensure that a machine-generated translation will be of publishable quality and useful to a human, it must be reviewed and edited by a human. It has, however, been asserted that in certain applications, e.g. product descriptions written in a controlled language, a dictionary-based machine-translation system has produced satisfactory translations that require no human intervention. Information from Wikipedia
is available under the terms of the GNU Free Documentation
License
E-mail this article to your colleague! Need more translation jobs? Click here! Translation agencies are welcome to register here - Free! Freelance translators are welcome to register here - Free! |
|
|
Legal Disclaimer Site Map |