|
 |
 |
| Home | More Articles | Join as a Member! | Post Your Job - Free! | All Translation Agencies |
|
|||||||
|
|
Translation memory 2.0
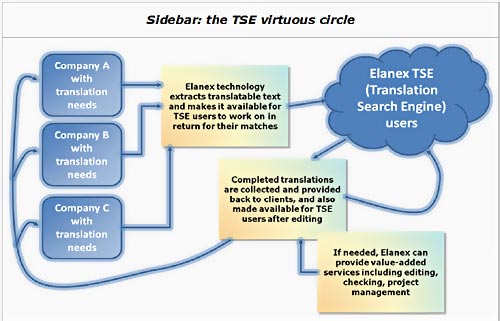
But two key problems remain: for any company, translation remains an extremely expensive proposition – it can often double the cost of a website or of creation of marketing materials. On a larger scale, the whole translation ecosystem today is inefficient: vast quantities of the world’s written material have yet to be translated, while the small quantity of material that actually has been translated contains large quantities of similar material, all paid for independently by individual private firms. In other words, the same sort of problem exists in the translation industry that existed in the early days of the internet: lots of valuable, useful information exists, but where is it? Interestingly enough, the solution may also be the same: a centralized, easily searchable, easy to use repository – in this case, of the world’s translations. Elanex TSE (Translation Search Engine) The biggest benefit of translation memory is not the tool itself, but the actual content: in other words, the memory. For most translators purchasing a translation memory system is equivalent to purchasing a word processor – it’s very convenient when you want to write an article, but it doesn’t actually write the article for you.
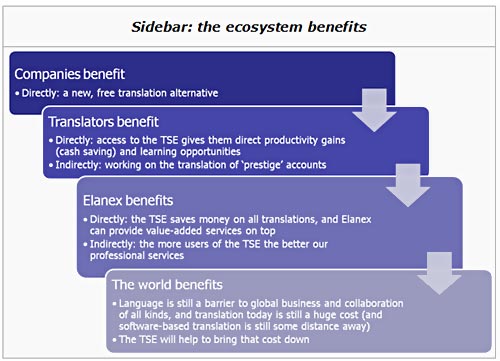
Part of the reason is technology – creating, managing, and quickly searching a gigantic database containing tens, hundreds or even thousands of millions of sentences was an impractical proposition ten years ago. A bigger reason was the ‘paradigm’ that existed when translation memory first arrived – most software was still installed on local computers, and the software itself did not typically communicate with software installed on other computers. Perhaps the biggest reason of all, though, is that in an industry where translators create and sell ‘words for a living’, re-using the words they create is seen as the right to earn a return on the investment made by the creator. If a translator can re-use an existing translation for a new client, the translator has saved some time, and therefore made more money. For a company, this rationale is different; the company can save dramatically by not having to translate the same words and phrases again when they appear in new documents. However, the world has changed – in many ways – and a better solution is now available: the TSE (for Translation Search Engine). A new paradigm emerges The watchwords in today’s emerging society are ‘networked’, ‘open source’, ‘software as a service’, ‘usergenerated content’ and so on. The key transition is that in a networked economy, it makes the most sense for people to have access to and build on the work of others, whereas in a closed economy, it made the most sense for people to act as ‘gatekeepers’ to their own private repositories of information. Hence, intellectual property of many kinds is moving to an ‘open source’ kind of model – where companies can still ‘sell’ the software (by providing value-added services on top of it – think RedHat, MySQL or SugarCRM), but where the intellectual property itself is free– (as in freedom of speech) –ly available for all to improve and extend. In the case of the TSE, this principle enables a whole new alternative for companies and translators: access to a gigantic repository of existing high quality translations, which through the power of pattern matching (or ‘fuzzy’ matching as it’s typically known in a translation memory context), can be re-used to reduce or eliminate new translation. For companies, the benefit is obvious – the TSE provides a brand new way of getting high quality translation done, which provides the ‘best of both worlds’ when compared to the two main existing solutions today (fully human translation, and fully automated translation): the translation quality is high, since it was created by humans; the cost is greatly reduced, since much of the heavy lifting has already been done. For individual translators, the benefit is also clear – if translation memory systems which contain no prior translations off-the-shelf are useful, then the same system pre-loaded with millions of top quality translations for a freelancer to leverage would be infinitely more useful. In our own tests, the TSE currently saves around 5% of a translator’s time – which may not sound like much, but it ‘translates’ (if you’ll pardon the pun) to around a day a month, which is a pretty significant productivity gain for anyone. What is less obvious is that the ecosystem as a whole benefits. The TSE does not ‘eliminate translator jobs’ – far from it. Only a tiny, tiny fraction of the world’s content is available today in multiple languages – most websites are still in the language of their creator only; most of the world’s intellectual property (in the form of patents, academic theses and papers and so on) is still in a handful of languages at best; even most of the world’s news remains untranslated. As long as content remains untranslated, there are commercial opportunities not yet being exploited; by making it cheaper for companies to exploit those opportunities, the ‘rising tide floats all boats’.
And who pays for it? As with open source software, the first question is ‘if it’s free, who pays for it?’, and the answer is also the same: the basic rules of economics still apply, but a level of indirection has been introduced which makes a new system work. In the case of the TSE, when translators search within the TSE for matches to existing translations, the TSE will only return matches if they’re actually found (unlike an automated translation solution, which would come up with its ‘best guess’ for every sentence). Instead of paying for these matches, users contribute their own translations, translations of items presented by the TSE to the translator, or other types of work such as editing other contributions. In other words, a translator’s benefit is clear – an extra productive day per month. In return for this benefit, the translator is contributing more content – in turn making the system more useful for other translators. A company benefits from free or low cost translation – and all that is required in turn is to allow the human translators who do the rest of the work to put that material into the TSE. With no extra cost to anyone, and with savings for both translators and companies, a system has emerged which makes the whole translation process more efficient. Where will it all end? Today’s fully automated ‘machine translation’ solutions rely on statistical techniques for analyzing large bodies of text. This is an improvement over first generation ‘rulebased’ systems, which could not develop sophisticated enough ‘rules’ for how humans actually construct sentences – one of the reasons it’s an improvement is that since the source material for statistical systems is real translation, the material generated by the systems sounds more natural, even if it’s wrong (somehow the mistakes are more ‘human’, in the same way that typing errors made by humans are more natural than the type of errors made by OCR software).
However, statistical analysis is not how humans talk – humans use language as a representation of how they think, and the language they create has all the flexibility of thought itself. Computers are still some distance from replicating thought. Translation memory therefore provides an alternative rather similar to the approach Big Blue takes to chess – a form of brute force. If you can’t create a translation, then look it up! Translation is a barrier to international trade, to global communication, and lack of it is one reason why some cultures have a hard time understanding each other. Anything that can be done through technologies such as the TSE to reduce translation costs – especially if they do not destroy a thriving human industry as an accidental byproduct – can ultimately help to make the world a better place. Jonathan Kirk ClientSide
News Magazine - www.clientsidenews.com
E-mail this article to your colleague! Need more translation jobs? Click here! Translation agencies are welcome to register here - Free! Freelance translators are welcome to register here - Free! |
|
|
Legal Disclaimer Site Map |