|
 |
 |
| Home | More Articles | Join as a Member! | Post Your Job - Free! | All Translation Agencies |
|
|||||||
|
|
Using XML For Localization
Unicode - While the encoding of a saved document can be anything, the character set of a parsed XML document is always ISO 10646/Unicode and therefore can include characters in most of the languages used today. Not only can the content of the XML files consist of almost any Unicode characters, but the names of elements and attributes can also be made of non-ASCII characters. For instance, the document shown below has Japanese and Russian content, and the element and attribute names are in Russian. Listing 1 - Non-ASCII XML document: <?xml version="1.0"?> <Собрание версия="2.0"> <Объект id="12"> <НомерОбъекта>12-3456-0050</НомерОбъекта> Encoding Identification - One of the main sources of problem during the process of localizing almost any type of data is related to opening the files using an incorrect encoding. XML solves this issue by providing a clear mechanism that always ensures (if applied properly) the identification of the encoding used to save the document. Escape Mechanism - XML also offers a safe way to escape extended characters that are not supported by a given encoding. This allows the document to contain any characters, even when they are not supported in the encoding the document is using. The hexadecimal form (&#xHHH;) and the decimal form (&#DDD;) use both the Unicode code-point value of the characters. For example, the Greek capital letter Omega (Ω) can be escaped as Ω or Ω if a given document uses an encoding where the Greek alphabet is not supported. Language Identification - Since an XML document can store data in different languages, it is important to be able to identify the language of the content. The XML namespace offers an attribute for this: xml:lang. The values of xml:lang are the same as the ones for the LANG attributes in HTML. They are defined by the RFC 3066 (an update to the RFC 1766), allowing 2 and 3-letter language codes, with an optional 2-letter country code. For instance: xml:lang="ar" indicates Arabic in general, while xml:lang="ar-IQ" identifies Arabic for Iraq. Note that, unlike other attribute values, the values of xml:lang are not case sensitive. Note also that the current values offered by RFC 3066 do not cover all needs of localization. For instance, there is currently no code for Latin-American Spanish; and there is no way to make a distinction between different scripts such as Azeri in Cyrillic script and Azeri in Latin script. Transformation Mechanism - In addition to the features of XML, some XML-related technologies provide efficient capabilities to facilitate the implementation of XML multilingual solutions. For example, XSLT is a powerful declarative language to manipulate XML data. It uses XPath, the standard mechanism to point to any node in an XML document. Both XSLT and XPath offer internationalization features such as language identification, sorting, numbers formatting, itemization using various digit sets, and so forth. Rendering - Lastly, two other technologies related to XML, XSL (also called XSL-FO for XSL Formatting Object) and CSS (Cascading Style Sheets), confer to XML a powerful and well internationalized framework to render content. Mixed with the possibilities offered by XSLT, you can present any given XML document in a wide variety of outputs. Migrating
to XML There are three ways to integrate XML into your process:
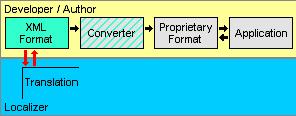
Scenario 1: As a temporary source The localizer uses a filter to convert or extract/merge the original format to XML, back and forth. In this first scenario, nothing changes for the developer or the author of the documentation. The localization provider can take advantage of XML to fit the proprietary format into an existing localization process (including for example, TM leveraging, terminology management, etc.).
Scenario 2: As an alternate source The developer/author works in XML and utilizes a one-way converter to create the file normally used by the application. This is an attractive solution if you need to keep most of your process untouched. By developing one conversion tool to go from your new XML format to your old proprietary format, you keep the benefits of an existing process, and the advantages of providing XML data for the localizer. Converters from XML to another format are usually not costly to develop, in many cases a simple XSLT template will do.
Scenario 3: As the original source The original format is in XML. This is obviously the best way to integrate XML within your architecture. One type of documents that can be easily migrated to this is HTML. The official hypertext file format recommended by the W3C is now XHTML, not HTML. The conversion from HTML to XHTML can be easily done, even automatically in many cases. The most important aspect is to move the XML format into the developer/author domain. By doing this, you allow the developers and the authors to use metadata directly within the original source file, ultimately giving them much more control on what happens to the data during the localization. Taking
Advantage of XML
In some cases, you can go one step further and use existing XML vocabularies instead of inventing your own. This will increase interoperability for your data. In the passed years, several specialized XML applications have been developed for particular purposes:
Using these formats when appropriate can bring many additional benefits. Translating
XML Documents
One way to work around this last problem is to modify slightly the original file to have a better input for the tools partially XML-impaired. For example, the XML document below has only one element content to be translated: "Cancel". However, very few tools will be able to set the necessary conditions for that because the case is too complex for them: translate only the content of any <data> element if it has an attribute type set to "text", and if it is inside a <component> element that has an attribute type set to "caption". Listing 2 - Example of UI description in XML: <?xml version="1.0"?> <dialogue xml:lang="en-gb"> <rsrc id="123"> <component id="456" type="image"> <!-- Do not translate --> <data type="text">images/cancel.gif</data> <data type="coordinates">12,20,50,14</data> </component> <component id="789" type="caption"> <!-- Translate --> <data type="text">Cancel</data> <data type="coordinates">12,34,50,14</data> </component> </rsrc> </dialogue> One method to address this type of issue that will work with any tool is to reduce the conditions into a new temporary element. For instance, add an element <tbt> (to be translated) where the content needs to be localized. The tools can then use a simple condition: translate the content of any <tbt> element. If the document has to be validated during the localization process, you may have to declare it as part of a different namespace, otherwise you can use it directly and make sure to remove it after localization. Listing 3 - Example of UI description in XML with extra element for translation: <?xml version="1.0"?> <dialogue xml:lang="en-gb"> <rsrc id="123"> <component id="456" type="image"> <!-- Do not translate --> <data type="text">images/cancel.gif</data> <data type="coordinates">12,20,50,14</data> A simple XSL transformation template can be used to automate the changes as shown below. Listing 4 - XSL Transformation for adding special translation elements: <?xml version="1.0" ?>
<xsl:stylesheet
xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
version="1.0">
<xsl:output encoding="utf-8" />
<xsl:template match="node()|@*">
<xsl:copy>
<xsl:apply-templates select="node()|@*"/>
</xsl:copy>
</xsl:template>
<xsl:template
match="//component[@type='caption']/
data[@type='text']">
<xsl:copy>
<xsl:apply-templates select="@*"/>
<tbt><xsl:apply-templates/></tbt>
</xsl:copy>
</xsl:template>
</xsl:stylesheet>
In addition to indicating what element content and/or attribute values need translation, you also need to provide some other information to the localizer:
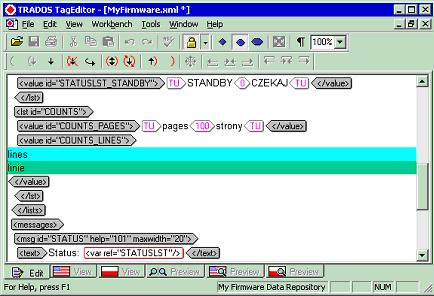
Just like for other file formats, there are various strategies for translating XML documents. The first option is to use an XML-specialized translation tool that will allow you to edit the text directly into the original format, as shown below with Trados TagEditor:
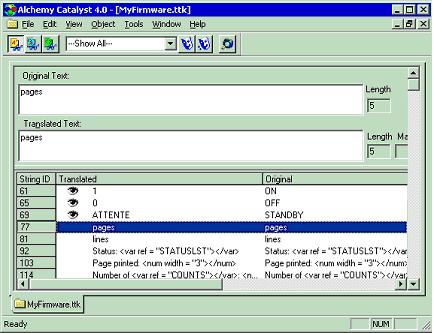
As many XML documents are simple repositories of data that are used in a context different from the way they are stored, seeing the original file may not always be a big advantage. The second option is to use tools that extract the translatable text into a database and present it to the localizer in a tabular form. For instance, Catalyst, from Alchemy Software, uses this mechanism as shown below:
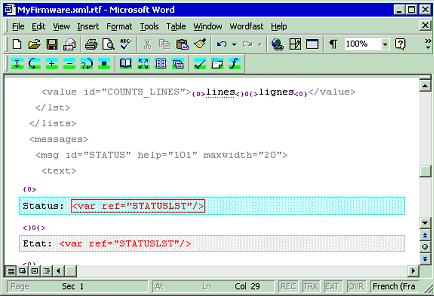
Such applications usually offer a preview method that reconstructs the original format and displays it, so the translator can see the data in context. Obviously the same limitations as in the first option apply here as well: sometimes XML files are simply not the best place to see the text in the context it will be used. Finally, the last option is to prepare the XML document with a utility that adds a color-coded RTF layer on top of the content. This way the file can be opened and translated in a classic word-processor like Word. This is illustrated below with Wordfast used as the translation tool:
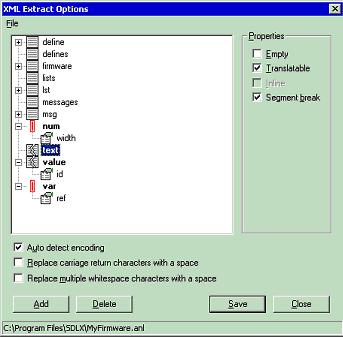
This method has the advantage of being more flexible regarding the choice of translation tool you want to use (or if you do not want to use any translation tool). It may also be more accommodating if the original format is not very well supported by translation tools: you can always add manual formatting to delimit the translatable parts from the sections to leave untouched. Regardless of the method utilized, at some point the localizer has to create some sort of definition file where localization-related information for the format to translate are stored: what parts of the content needs translation and what parts need to be left untouched, the name of the translatable attributes, and so forth. For example, the following screen shows how this is done with SDLX from SDL International:
Each tool has its own way of storing this type of information, but overall, they all use more or less the same information. At some point, the standardization of both the information needed and a common format to specify it would be helpful to everyone. One of the attractive aspects of XML is that by applying different style-sheets and/or transformation templates to the document you can provide different views of the data. For example: one showing the data as it will be formatted in the final output, one displaying only items that have changed, and another showing source and target side by side for easier comparison, and so on. Using XSLT allows you to go even further. You can create templates that validate the document and display the items with errors. If the XML format you are using is one of the standard formats such as XLIFF, you can develop a library of different templates offering a wide range of functionalities that you can re-use across different original formats. In the example below, a simple template provides a comparison between the source and the target text, flagging any target entries where an ending exclamation point is missing. You can apply similar methods to verify (according each language) other punctuation requirements, preservation of leading or trailing spaces, missing or extra variables, etc. This specific example uses a very useful extension in the Microsoft XSL engine: the ability to call scripts in the template. Listing 5 - XSLT template for verification: <?xml version="1.0" encoding="iso-8859-1" ?>
<xsl:stylesheet
xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
version="1.0"
xmlns:msxsl="urn:schemas-microsoft-com:xslt"
xmlns:rws="http://www.translate.com/xml-verification">
<msxsl:script language="JScript"
implements-prefix="rws">
<![CDATA[
var g_nCount = 0;
function ErrorCount () {
return(g_nCount);
}
function CheckLastChar(p_Src, p_Trg, p_Char) {
var sSrc = new String(p_Src.nextNode().text);
if ( sSrc.length<1 ) return("");
var sTrg = new String(p_Trg.nextNode().text);
if ( sTrg.length<1 ) return("Empty Target");
var cTmp = sSrc.charAt(sSrc.length-1);
if ( cTmp == p_Char ) {
if ( cTmp != sTrg.charAt(sTrg.length-1) ) {
g_nCount++;
return("Missing character '" + p_Char +
"' at the end of the target text.");
}
}
return("");
}
]]>
</msxsl:script>
<xsl:template match="text()"/>
<xsl:template match="comment()"/>
<xsl:template match="//alt-trans"/>
<xsl:template match="/xliff">
<html>
<head>
<title>Verification</title>
</head>
<body>
<h1>Verification</h1>
<table border="1" cellspacing="0" cellpadding="3">
<xsl:apply-templates/>
</table>
<p>Number of errors =
<b><xsl:value-of select="rws:ErrorCount()"/></b></p>
</body>
</html>
</xsl:template>
<xsl:template match="//source">
<xsl:variable name="R1"
select="rws:CheckLastChar(.,../target,'!')"/>
<xsl:if test="$R1!=''">
<tr>
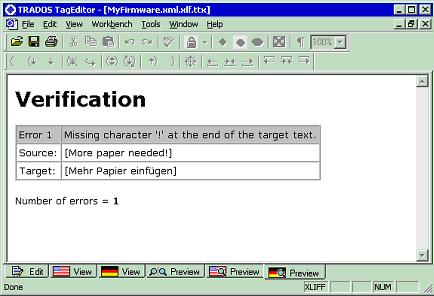
This type of mechanism allows you to extend and easily customize the capabilities of any translation tool. Most of them offer a function to see a preview of the translation, the user can observe directly the results of the validation in his/her working environment, as show below for TagEditor:
There are still a few pieces that need to be added to the overall XML framework. A. Localization
Properties Listing 6 - Localization properties for the document in Listing 2 on page 7: <?xml version="1.0" ?>
<locprop version="0.1">
<rules name="Example1" root="dialogue">
<element-defaults localize="no"/>
<attribute-defaults localize="no"/>
<rule item="//component[@type='caption']/
data[@type='text']"
localize="yes"/>
</rules>
</locprop>
B. Localization
Directives Localization directives are to be used as metadata, using the standard XML namespace mechanism. This allows you to embed, within the document of your own document type, common directives that can be understood by any authoring and translation application. You can imagine that at some point an author could simply highlight a section of the text and click a button to make it non-translatable, or to identify it as a glossary term, etc. For example, the XHTML document on the next page includes a few of those possible types of directives. Listing 7 - Localization directives in an XHTML document: <?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "DTD/xhtml1-strict.dtd"> <html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en" lang="en" xmlns:loc="urn:the-localization-directives-standard"> <head><title loc:id="100">Title</title></head> <body> <h1 id="101">Introduction to <loc:span term="yes"> Document Management</loc:span></h1> <p id="102">Our company, <loc:span localize="no"> Infinite Wisdom Inc.</loc:span>, provides quality courses on how to manage your documentation.</p> </body> </html> Such vocabulary could also be re-used by schema developers to include localization-specific attributes in their own vocabularies, the same way xml:lang is used today.
E-mail this article to your colleague! Need more translation jobs? Click here! Translation agencies are welcome to register here - Free! Freelance translators are welcome to register here - Free! |
|
|
Legal Disclaimer Site Map |
 XML
is one of the safest, most powerful and flexible ways to
store, manipulate, localize and present data in different
languages. With the vast array of internationalization features
and companion technologies, XML provides many advantages
in translation and localization projects.
XML
is one of the safest, most powerful and flexible ways to
store, manipulate, localize and present data in different
languages. With the vast array of internationalization features
and companion technologies, XML provides many advantages
in translation and localization projects.