 |
 |
 |
| Home | More Articles | Join as a Member! | Post Your Job - Free! | All Translation Agencies |
|
|||||||
|
|
Systran MT/TM integration
SYSTRAN’s goal is to better describe languages, the gateway to continue improving the quality of automatic translation. Today SYSTRAN is the market leading provider of language translation software products and solutions for the desktop, enterprise, and Internet that facilitate communication in 52 commercially available language pairs and in 20 vertical domains. Almost 20 additional language pairs have been developed for specific projects or customers. SYSTRAN is the choice of leading global corporations, portals that include AltaVista™, Apple, Google™, Yahoo!®, and governmental institutions throughout the world like the US Intelligence Community. Use of SYSTRAN products and solutions enhances multilingual communication and increases user productivity and time-savings for B2E, B2B, and B2C market segments as they deliver real-time language solutions. Although there is a wide spectrum of SYSTRAN products and solutions to choose from, each allows users to instantly translate any written text for gisting (understanding the general idea of what is written, such as quick understanding of foreign language Web content) and for publishing (near-perfect translations that also require post-editing, like user guides, technical support content, and other common localization projects). When used for publishing purposes, professional users often combine MT and TM’s (translation memories). The simpler integration applies TM’s first, and MT on “no match” segments as a default translation. A richer approach uses TM’s and, more generally user feedback, to supply MT resources. It is in the context of the second approach that we provide an overview of how SYSTRAN’s translation engines work, highlighting the importance of the linguistic descriptions, how existing TM’s can be reused to customize the translation engines, and available tools for managing Translation Memory and User Terminology within a translation workflow based on MT. LINGUISTICS AND THE IMPORTANCE OF DESCRIBING LANGUAGES Two key elements distinguishing SYSTRAN’s MT system from the others are that it’s an incremental system and is deterministic. The system is designed to produce incremental translation quality results between versions which can be easily validated by users. Additionally, the system produces deterministic output, meaning the results are consistent and based on available resources. As a result, users are able to interact with the system to modify results by customizing linguistic resources. It all starts with the three types of linguistic descriptions provided for each language pair (source language to target language) implanted in the system: Analysis, Transfer, and Generation. The following diagram illustrates the process for translating a source language sentence into a target language sentence. The deeper the source language analysis, the smaller the transfer will be (and the smaller the effort to build new language pairs).
• Global Document Analysis considers the input text as one unit and performs several rounds of analysis that identify important elements that help describe the source language. These include language identification at the paragraph level, the named entities (such as dates and proper nouns) that define the local terminology, and subject detection of the document which enables the system to automatically select preferred meanings by domain. • Grammatical Analysis provides the system with the data required to create the internal representation of each by displaying the complete linguistic structure of each sentence. Included are part of speech for each word, the syntagm to which they belong, the relationship between different entities, and the function of main elements (verb, object, subject, and complement). This deep description builds a hierarchical representation of the dependencies between the different elements. The system’s analysis involves several rounds represented by a sequence, each of which has several dependencies to other components, including:
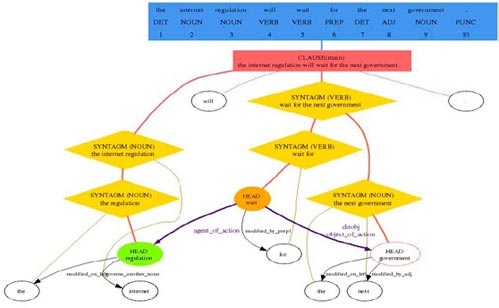
2. The description of the transfer from the source language to target language focuses on the transfer of structures and the transfer of the lexicon. It is the only description dependent on both the source and target languages. For instance, the internal analysis of the previous sentence is transferred (from English to German) into the structure represented in following figure. 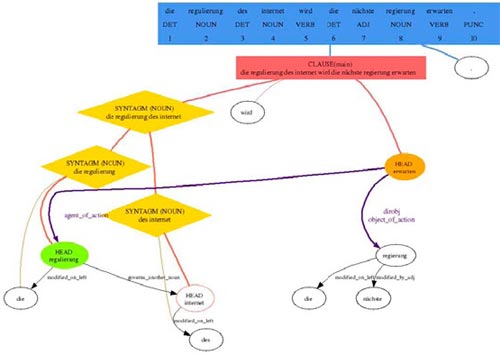
3. The description of the target language also referred to as the generation. These three linguistic descriptions are based on linguistic resources; monolingual for the analysis and generation or bilingual for the transfer. There are two primary types of resources: rules and dictionaries. Dictionaries describe individual terminological units. Rules generalize these descriptions while providing high-level descriptions of linguistic phenomena. Typically linguistic resources are very large, and for some language pairs can reach up one million entries. Most of these resources can be learned (with supervised semi-automatic extraction tools) from a bilingual corpus – such as existing translation memories - and easily therefore adapted to specific domains, which means the translation is customized. In comparison, the rules count is smaller but rules rank much higher in terms of complexity and require linguistic expertise for creation and maintenance. ARCHITECTURE SYSTRAN systems are highly modular and are based on an XML workflow, a mechanism enabling communication between users and the different modules, and between the different modules themselves. This mechanism provides interaction between users and the system’s internal rules. The interaction between users and internal rules is enabled by rich interactive tools embedding MT. For high productivity, professional users must be able to understand the translation process, as well as interact with the rules and resources in order to fine-tune their translations. An example of a rich interactive tool is the SYSTRAN Translation Project Manager, a translation workbench available in select SYSTRAN products and solutions. All of the features mentioned below are included in this tool.
SYSTRAN PRODUCTS SYSTRAN’s array of products and solutions for the desktop, enterprise, and Internet help enterprise and home users understand foreign language content in real-time and create multilingual documents. Released in February of this year, SYSTRAN 6 brings 12 new language pairs, more than one million new terms created from aligned data, a dictionary lookup, a comprehensive environment for post-editing and QA that includes terminology extraction, flexible TM’s, collaborative dictionary management, built-in comparators, and other tools to efficiently optimize translations in a cost-effective manner. Noteworthy rich interactive tools and technology associated to the translation engines follow: • SYSTRAN Translation Project Manager (STPM) is a “translation workbench” used to create, manage, and refine localization projects consisting of hundreds of files. Using STPM users perform side-by-side comparisons between original and translated documents and affect changes to both, as well as add terms to User Dictionaries and process dictionary updates. In addition, STPM offers a selection of powerful built-in review tools, including terminology review, analysis of the original document, full sentence review, use of alternative meanings, and others for applying, reviewing, and building TM’s and other advanced features. • SYSTRAN Dictionary Manager (SDM) allows users to create and manage three levels of linguisti c data types to improve translation quality. The data types are:
• SDM is based on IntuitiveCoding, a proprietary SYSTRAN technology that allows users to massively import and manage entries in User Dictionaries. • Dictionary Lookup provides additional contextual information for alternative meanings of selected source language terms. Users can select a term at any time across multiple dictionaries covering the SYSTRAN Main Dictionary, 20 SYSTRAN Domain Dictionaries, User Dictionaries, and other integrated dictionaries. 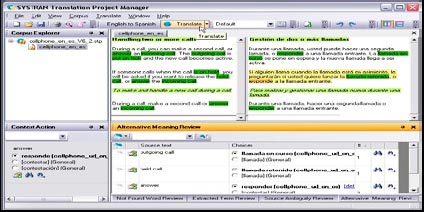
Set translation choices and customize terminology with contextual review tools in SYSTRAN Translation Project Manager. CONCLUSION It is essential to customize the translation engines for use within a localization workflow. This customization process is based on a variety of rich user-interactive tools that leverage existing TM’s and exploit the post-editing effort to create complementary linguistic resources. Based on linguistic tools, this customization process advances the quality of the linguistic descriptions involved in the translation process and progressively increases overall translation quality. Source sentence
ClientSide News Magazine - www.clientsidenews.com
E-mail this article to your colleague! Need more translation jobs? Click here! Translation agencies are welcome to register here - Free! Freelance translators are welcome to register here - Free! |
|
|
Legal Disclaimer Site Map |

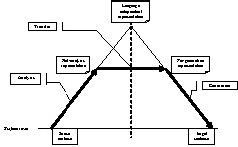 1.
The description of the source language, also referred
to as the analysis is composed of the following analyses:
1.
The description of the source language, also referred
to as the analysis is composed of the following analyses:
